Asi každý z nás se už někdy ocitnul v situaci, kdy nervózně přešlapoval na zastávce hromadné dopravy a několikrát za minutu si pohledem kontroloval své hodinky, přičemž marně vyhlížel, kdy se zpoza zatáčky vyřítí onen vytoužený přibližovací prostředek na cestu do práce či do školy. Věřte nebo ne, služba, která téměř v reálném čase trackuje veškeré dopravní prostředky pohybující se po městě, již několik let dobře funguje v Brně a nyní v testovací fázi dokonce i v Jihlavě.
V Praze, největším a hlavním městě České Republiky, byste však podobnou službu hledali jen stěží. Příčinou a hlavním důvodem je, že Dopravní podnik hlavního města Prahy, i přes platnost zákona o svobodném přístupu k informacím, v minulosti opakovaně odmítnul zveřejnit data o aktuálních polohách svých dopravních prostředků, s odvoláním na současnou bezpečnostní situaci v Evropě a nutnost dodatečných úprav svých dispečerských programů, což by podle DPP představovalo nadměrnou finanční zátěž v řádech několika milionů korun.
Ve spolupráci s datovou platformou Golemio, která je součástí projektu Smart Prague a která zdarma poskytuje různé datové sady jako například informace o aktuální obsazenosti parkovišť, kvalitě ovzduší, využití cyklo dopravy, chytrých laviček, stavu plnosti popelnic a další, jsme se v rámci projektu OpenDataLab rozhodli realizovat studentský projekt, který by se přiblížil tomu brněnskému. Platforma totiž obsahuje i datovou sadu aktuálních poloh příměstských linkových autobusů v Praze a každých 30 vteřin tak přichází z API čerstvá zpráva (JSON) o tom, kde se který autobus zrovna nachází.
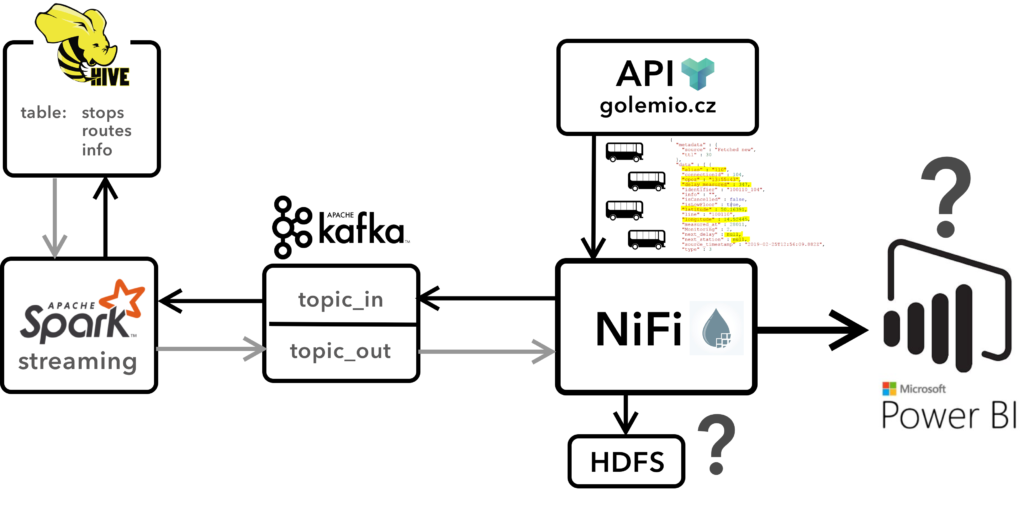
Tuto informaci přebírá centrální a klíčový prvek, na kterém jsme se rozhodli celé řešení postavit. Jedná se o software Apache NiFi, poměrně intuitivní a open-sourcový nástroj pro datové flow-based programování. Těm, kterým tento termín nic neříká, pomůže představa konvenčního vodovodní potrubí, v němž tečou data určitým směrem. Při své cestě prochází přes různé filtry a ventily vykonávajícími nad těmito daty datové operace. Vzájemným propojením těchto filtrů poté vznikne ucelený datový tok.
Co se do obsahu příchozí zprávy týče, informace o aktuální poloze není to jediné, co se uvnitř ukrývá. Současně s ní totiž přichází i další zajímavé atributy daného spoje. Příkladem je informace o aktuálním zpoždění, číselný identifikátor poslední navštívené zastávky, nebo to, zda se jedná o autobus nízkopodlažní či nikoliv. Všechny zmíněné věci jsou sice pozoruhodné, ale s jejich počtem jsme se spokojit odmítli. Na jejich základě jsme se nicméně rozhodli dopočítat a přidat další atributy, které nám přišli z uživatelského hlediska perspektivní. V tomto bodě přichází na scénu Kafka a Spark-Streaming.
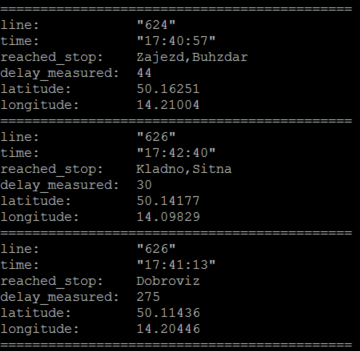 Ukázka dat
Ukázka dat
Rovněž se jedná o hadoopovské open-source nástroje od Apache, ovšem jejich účel je od NiFi diametrálně odlišný. Kafka je ve své podstatě transakční logovací nástroj, který se používá pro budování real-time datových přenosů a streamingových aplikací. Naproti tomu Spark je engine pro distribuované a paralelní operace s daty napříč celým clusterem. Jeho nespornou výhodou je práce v operační paměti, což umožňuje mnohem rychlejší zpracování než například u technologie MapReduce. Spark Streaming je poté nadstavbou Sparku, obsahující nástroje, které umožňují práci se streamovanými daty v téměř reálném čase.
V našem případě hraje Kafka roli prostředníka mezi NiFi a Spark Streamingovou aplikací. Ve své podstatě mezi nimi vytváří abstraktní komunikační kanál, který je pomyslně navzájem propojuje. NiFi parsuje a předzpracovává informace obsahující základní, z API přebrané informace o jednotlivých autobusech. Tyto data odesílá do Kafka topicu, odkud si je přebírá Spark Streamingová aplikace, která v tuto chvíli umí záznam přečíst a na základě identifikátoru zastávky a jejímu jmennému ekvivalentu uloženému v HIVE tabulce vrátit její název, tuto informaci agregovat s původními daty a opět odeslat zpět do Kafky, odkud si ji NiFi opět přebírá zpět. Obohacená data jsou po průchodu pomyslným potrubím následně streamována do služby PowerBI pro vizualizaci. Tímto byla dovršena první etapa našeho projektu a prokázán POC daného řešení.
Při testování se postupem času ukázalo, že PowerBI není příliš šťastné řešení, neboť tento nástroj je primárně určen pro vizualizaci dat finančního charakteru a není příliš vhodný pro podobný typ úloh. S tímto, i dalšími problémy se nadále budou vypořádávat studenti, kteří se postarají o následující rozvoj. Budou se tak moci seznámit s moderními Big Data technologiemi, a zároveň se přitom podílet na realizaci zajímavého projektu. V plánu je například rozšíření portfolia dostupných atributů o odhad zpoždění, informaci o následující zastávce nebo kontrolu vybočení autobusu z obvyklé trasy.
Tento text byl poprvé zveřejněn na webu opendatalab.cz