Každý z nás už určitě slyšel o funkcionálním programování. Je to dnes hodně populární styl a některé funkcionální prvky se pomalu začínají integrovat (nebo již integrovaly) i do klasických objektových jazyků, například Javy.
Definic, co přesně je funkcionální programování a na čem celé paradigma stojí, je na internetu mnoho. Některé jsou nepřesné, některé hodně povrchní a představa o funkcionálním programování se zvláště u lidí, kteří s ním nemají zkušenosti, velmi liší.
Cílem tohoto článku není snaha o detailní vysvětlení, co je funkcionální programování, ale demonstrace jednoduchého příkladu s rozdíly mezi funkcionálním (FP) a objektově orientovaným (OOP) programováním.
Text zmíní některé výhody a pokusí se i naznačit práci s nejzákladnějším funkcionálním návrhovým vzorem. Po přečtení byste měli dojít k poznání, že i pouhá znalost funkcionálních přístupů může významně zlepšit váš kód napsaný v nefunkcionálním jazyce.
Recept na kuřecí marsalu
Inspirací pro text je hezkým ukázkový příklad na webu. Místo lehce nezdravého receptu na Tiramisu použijeme jako názorný příklad recept na kuřecí marsalu z kuchařky pro inženýry.
Nejdůležitější pro implementaci postupu je koncový diagram, který znázorňuje celý postup, jak si takovou marsalu uvařit:
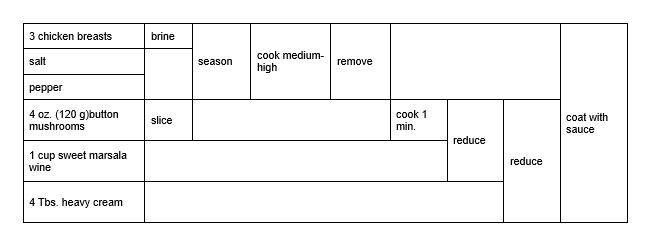
Objektový přístup
Kroky a ingredience pro přípravu marsaly jsou jasné. Kdybychom se na přípravu koukali očima objektového paradigmatu, implementace bude spočívat v metodě, která nejspíše bude přijímat všechny ingredience jako vstupní parametry a bude vracet hotovou marsalu. Konkrétní implementace by mohla vypadat následovně:
def cookMarsalaChicken(chickenBreast: ChickenBreast, salt: Salt, pepper: Pepper, buttonMushrooms: ButtonMushrooms, sweetMarsalaWine: SweetMarsalaWine, heavyCream: HeavyCream): ChickenMarsala = { return new ChickenMarsalaBuilder() .brine(chickenBreast) .season(chickenBreast, salt, pepper) .cookMediumHigh(chickenBreast, salt, pepper) .remove(chickenBreast, salt, pepper) .slice(buttonMushrooms) .cookMushrooms(buttonMushrooms) .reduce(buttonMushrooms, sweetMarsalaWine) .reduce(buttonMushrooms, sweetMarsalaWine, heavyCream) .coatWithSauce(chickenBreast, salt, pepper, buttonMushrooms, sweetMarsalaWine, heavyCream) .build() }
Implementace je v jazyce Scala, protože je to funkcionálně objektový jazyk, a lze tedy demonstrovat implementaci za použití obou paradigmat a sledovat rozdíly. Principy jsou ale nezávislé na použitém jazyce.
V ukázce je použit objektový návrhový vzor Builder. S trochou dobré vůle je možné, že výsledek bude podle očekávání. Teď je nutné si položit zásadní otázku, co je na tomto kódu špatně. Proč je pořadí volání metod takové, jaké je? Kompilátor nám klidně dovolí všechno přeházet nebo nějaké volání vynechat. Je to v pořádku?
Největší problém je, že metody mají tzv. side-effect, na který spoléhá zbytek kódu. Každá metoda mění stav ingrediencí. Metoda tedy předpokládá, že obdrží ingredience ve správném stavu. Pokud se zavolá v jiném stavu, tak výsledek nebude správný. Co s tím? Měli bychom generovat výjimku? V takovém případě by potom každá metoda generovala výjimky a každé volání by s tím muselo počítat a danou situaci ošetřovat.
Předpokládejme nyní, že metoda funguje správně. Náš kuchařský systém začne využívat hodně klientů a vaření marsaly se stane úzkým hrdlem, které zpomaluje celý systém. Chtěli bychom metodu nějak zrychlit. Je možné spouštět nějaké části paralelně? Převést takový kód na paralelní zpracování ale nebude vůbec jednoduché. Kupříkladu na první pohled není zřejmé, jaké metody jsou na sobě nezávislé a lze je tedy bezpečně paralelizovat.
Funkcionální přístup
Jak je uvedeno výše, byl zvolen jazyk Scala, protože je funkcionálně-objektový a lze v něm tedy kombinovat obě paradigmata. Nyní nastává čas na postupný převod příkladu do funkcionální podoby.
První věc, které se ve světě FP snažíme vyvarovat, je měnný stav. V FP se data modelují pomocí ADT (Algebraic Data Types), které jsou imutabilní (neměnná). S tím úzce souvisí další pojem pure-function a referenční transparence. Tyto vlastnosti stručně řečeno značí, že výstup funkce je závislý jen a pouze na svých vstupních parametrech a kromě výpočtu výstupu nedělá nic jiného (nemá žádný side-effect). Za použití těchto vlastností se nám kód změní následovně:
def cookMarsalaChicken(chickenBreast: ChickenBreast, salt: Salt, pepper: Pepper, buttonMushrooms: ButtonMushrooms, sweetMarsalaWine: SweetMarsalaWine, heavyCream: HeavyCream): ChickenMarsala = { val brinedChicken = brine(chickenBreast) val mixture = season(brinedChicken, salt, pepper) val cookedMixture = remove(cookMediumHigh(mixture)) val cookedMushrooms = cookMushrooms(slice(buttonMushrooms)) val reducedMushroomsWithWine = reduce(cookedMushrooms, sweetMarsalaWine) val reducedMushroomsWithCream = reduce(reducedMushroomsWithWine, heavyCream) return coatWithSauce(mixture, reducedMushroomsWithCream) }
Kód je podobný, ale na první pohled je vidět, že některá volání vyžadují předpřipravené ingredience. Metoda remove například potřebuje, aby nejdřív něco „bylo v troubě“ ß cookMediumHigh. Metoda reduce vyžaduje vařené houby, cookMushrooms vyžaduje nakrájené houby. Zde kompilátor kontroluje workflow přípravy za nás. Stačí dekomponovat problém na podproblémy, správně navrhnout datové typy, použít ADT a pure-functions, a o zbytek se postará kompilátor.
Tak jedna nevýhoda OOP implementace odpadla, co ty další? Co kdyby mohlo docházet k pádu každé jednotlivé funkce – a my přitom potřebujeme škálovat?
Monády
Vše za nás může vyřešit jeden funkcionální návrhový vzor – Monáda. Jedná se nejspíš o jeden z nejpoužívanějších funkcionálních návrhových vzorů vůbec. Ten vychází z matematické teorie kategorií a ano, i ostatní funkcionální návrhové vzory jsou dosti matematické, ale co je nejlepší abstrakce na světě? Matematika.
Tak co ta Monáda vůbec je a jak ji zde použít? Monáda vytváří abstrakci nad výpočtem a zapouzdřuje výsledek. Dále obvykle přidává nějaký side-effect, který je specifický pro každou implementaci tohoto vzoru. Všimněte si, že takto zabalený side-effect neporušuje referenční transparentnost. Návratový typ funkce je zapouzdřený v konkrétní implementaci monády a tedy side-effect je součástí signatury funkce.
Monáda má mnoho hezkých vlastností, ale ta asi nejdůležitější je možnost kompozice. Každá monáda implementuje funkce map a flatMap, pomocí kterých lze vytvářet složitější kompozice (bude ukázáno).
Nejjednodušší na vysvětlení bude ukázka příkladu s použitím konkrétní implementace tohoto vzoru. Zde použijeme ještě něco z vlastností jazyka Scala (konkrétně for-comprehension):
def cookMarsalaChicken(chickenBreast: ChickenBreast, salt: Salt, pepper: Pepper, buttonMushrooms: ButtonMushrooms, sweetMarsalaWine: SweetMarsalaWine, heavyCream: HeavyCream): Try[ChickenMarsala] = { return for { brinedChicken <- brine(chickenBreast) mixture <- season(brinedChicken, salt, pepper) cookingMediumHigh <- cookMediumHigh(mixture) cookedMixture <- remove(cookingMediumHigh) slicedMushrooms <- slice(buttonMushrooms) cookedMushrooms <- cookMushrooms(slicedMushrooms) reducedMushroomsWithWine <- reduce(cookedMushrooms, sweetMarsalaWine) reducedMushroomsWithCream <- reduce(reducedMushroomsWithWine, heavyCream) chickenMarsala <- coatWithSauce(mixture, reducedMushroomsWithCream) } yield chickenMarsala }
Zde je důležité upozornit na 2 aspekty:
- Každá jednotlivá funkce nově vrací výsledek obalený v konstruktu Try,
- Pro kompozici je použit přístup for-comprehensionmísto pouhého provolání funkce.
Try je jedna z implementací návrhového vzoru monáda. Monáda, jak již bylo řečeno, abstrahuje výsledek volání a nějaký side-effect. V tomto případě se jedná o side-effect, který způsobuje možnost pádu funkce. Try je abstraktní třída s potomky Success, který obdržíme, pokud vše dopadlo správně, a Failure pro opačný případ. Mezi další implementace monády patří například Option (Optional), který abstrahuje effect nepovinnosti a Future (Promise), který abstrahuje latenci (na tu se ještě podíváme dále).
Teď si možná kladete otázku, jak je možné, že to funguje? Jak je uvedeno v předchozím textu, každá monáda implementuje dvě funkce – map a flatMap. Ty umožňují kompozici více monád a co víc, starají se sami o ošetření chyb (error handling)! Pokud na Failure monádě zavoláme map/flatMap, nevykoná se vnitřní logika a výsledek bude opět Failure monád. Toto je takzvané monadické vyhodnocování – první chyba zastaví zbytek výpočtu. Pro kompletnost existuje ještě aplikativní vyhodnocování, které vyhodnotí všechny kroky a chyby kumuluje (viz vzor Applicative Functor).
Jaký je tedy přínos monadického vyhodnocování a error handlingu? V objektové ukázce bychom nejspíše využili výjimky. Celý Builder by v důsledku musel být obalený v try bloku, protože může selhat každé volání. Co však uděláme v ošetřující catch části? Pokud náš kód využívá další kód, tak by měl být o chybě notifikován. Můžeme tedy také vyhodit výjimku. Stejný problém bychom ale řešili na každé vrstvě aplikace. Monáda a monadické vyhodnocování tohle vše udělá za nás. Na nejnižší úrovni, kde může dojít k pádu, vytvoříme Success nebo Failure instanci Try a tu můžeme skládat dál a dál bez větších starostí.
Několikrát byly zmíněny funkce map a flatMap nad Monádou, ale v kódu k vidění nejsou. Za to může jazyk Scala a zázračný syntactic sugar – for-comprehension. Dané umožňuje imperativní zápis, který se však převede na tzv. chain map, flatMap a filter. Samozřejmě není nutné for-comprehension využívat, ale kód by nevypadal tak hezky:
brine(chickenBreast) .map(chicken => season(chicken, salt, pepper) .map(mixture => cookMediumHigh(mixture) .map(cookedMixture => remove(cookedMixture)) .... ) )
Zkompilovaný bytecode by vypadal úplně stejně, ale nejednalo by se o tak elegantní zápis.
Monáda je velmi silný nástroj. Umožňuje bezpečné abstrahování side-effectu na nejnižší vrstvě a map/flatMap umožňují vytvářet složité kompozice aniž bychom museli řešit error handling. Ke každému effectu lze přistupovat stejně.
Dalším zmíněným požadavkem bylo škálování. Již z implementace je jasné, jaké funkce je možné volat paralelně, takže by nebyl problém je přepsat s pomocí vláken. Lze to ale udělat o dost jednodušeji. Na latenci můžeme také nahlížet jako na side-effect a ten můžeme opět abstrahovat pomocí monády – Future. Implementace bude vypadat nečekaně úplně stejně (je to opět monáda), pouze návratový typ všech funkcí již nebude zabalený v Try, ale ve Future:
def cookMarsalaChicken(chickenBreast: ChickenBreast, salt: Salt, pepper: Pepper, buttonMushrooms: ButtonMushrooms, sweetMarsalaWine: SweetMarsalaWine, heavyCream: HeavyCream): Future[ChickenMarsala] = { return for { brinedChicken <- brine(chickenBreast) mixture <- season(brinedChicken, salt, pepper) cookingMediumHigh <- cookMediumHigh(mixture) cookedMixture <- remove(cookingMediumHigh) slicedMushrooms <- slice(buttonMushrooms) cookedMushrooms <- cookMushrooms(slicedMushrooms) reducedMushroomsWithWine <- reduce(cookedMushrooms, sweetMarsalaWine) reducedMushroomsWithCream <- reduce(reducedMushroomsWithWine, heavyCream) chickenMarsala <- coatWithSauce(mixture, reducedMushroomsWithCream) } yield chickenMarsala }
Future reálně při spuštění funkce pouze zaregistruje, že se něco má spočítat, ale výpočet se spouští v novém vlákně (neblokuje hlavní výpočetní vlákno). Díky této vlastnosti je opět možné vytvářet složité kompozice a silný typový systém se postará o to, že na výsledek se čeká jenom v částech, kde už opravdu potřebujeme hodnotu pro výpočet něčeho dalšího. Pro práci s výsledkem se běžně používá callback funkce, kterou je možné přidat pomocí onComplete typu Try[T] => U. A hle, znova Try. To znamená, že Future navíc abstrahuje možnost chyby, lze tedy ošetřit i chybový stav.
Shrnutí
Cílem článku nebylo detailně popsat funkcionální návrhové vzory, jazyk Scala nebo podat vyčerpávající přehled principů FP. Cílem bylo navnadit čtenáře k tomu, aby se zamysleli nad základními principy FP, a jaký mají důsledky, a aby po přečtení věděli, že existuje celá oblast funkcionálních návrhových vzorů.
Funkcionální řešení ukázkového příkladu se významně neliší od objektového zápisu, ale dodržením pár principů a s použitím vzoru Monáda, má kód úplně jiné vlastnosti. Je možné jej škálovat, vytvářet nad ním složitější kompozice a díky referenční transparentnosti bude i jednodušší testování (stačí pokrýt kombinace vstupů – výsledek na ničem jiném nezávisí).
Z vlastní zkušenosti lze potvrdit, že alespoň znalost výše uvedených principů může výrazně zvýšit kvalitu klasického objektového kódu. Mnohdy stačí, když se člověk jen zamyslí, jestli je opravdu nutné vytvářet implementaci, která je závislá na vnějším stavu, jestli je rozumné přidávat side-effect do metod, anebo jestli se tomu všemu nedá jednoduše a elegantně vyhnout.
Literatura