Myslíte si, že s pojmy jako je cohesion (soudržnost), loose coupling a encapsulation (zapouzdření) se člověk potká jenom v teorii nebo během studia? Není to tak a v tomto článku se pokusíme vysvětlit, jak vás tyto pojmy dokáží v praxi takříkajíc pěkně kopnout. Povídání o těchto pilířích dobrého objektového návrhu navíc okořeníme dalším tématem, kterému je dobré rozumět, a to synchronizací.
Na jednom z našich projektů jsme řešili problém s cachí, která se čas od času rozbila a zacyklila. Co to znamená? Podívejme se napřed, jak implementace cache vypadala.
Původní návrh
Cache byla implementovaná třídou CacheMap extendující LinkedHashMap.
LinkedHashMap je mapa, která si pamatuje predikovatelné pořadí prvků (k predikovatelnosti se dostaneme později). Překrytá metoda removeEldestEntry nám dovoluje rozhodnout, jestli má mapa smazat nejstarší prvek.
#cohesion
Je takový návrh dostatečně soudržný? Od cache požadujeme možnost vložit prvek, získat nebo smazat prvek podle klíče, vyprázdnit celou cache a také možnost zjistit počet prvků. V našem případě k tomu slouží metody put, get, remove, clear a size, které třída CacheMap zdědila od třídy LinkedHashMap. Víc toho naše cache nepotřebuje. Protože ale třída CacheMap rozšiřuje třídu LinkedHashMap, získali jsme navíc možnost volat metody putAll, keySet nebo třeba values, které ale naše cache nepotřebuje. Čím méně věcí třída řeší, tím je obecně soudržnější. Třída CacheMap je pěkně soudržnou mapou (ve smyslu implementace rozhraní Map), ale není to moc soudržná cache.
V kapitole o refactoringu si ukážeme, jak původní návrh zlepšit.
Zacyklení
Třída LinkedHashMap není thread-safe. Pokud více vláken současně mění strukturu mapy, třeba přidáváním prvků, musí být přístup těchto vláken k mapě synchronizovaný.
Zastavme se u toho, co může chyba v synchronizaci a rozbití vnitřní struktury mapy znamenat. Pro potřeby zapamatování pořadí udržuje LinkedHashMap prvky ve spojovém seznamu. Více vláken vkládajících současně prvky do mapy může způsobit jeho zacyklení. A kdy skončí iterace přes prvky zacykleného spojového seznamu?
Iteraci může provádět samotná LinkedHashMap při vkládání nového prvku, pokud je potřeba zvětšit hashovací tabulku. Vkládání jednoho prvku do cache tak může zablokovat všechny operace nad ní.
Představme si jednoho uživatele, kterému se nezobrazí stránka s důležitými daty nebo všechny uživatele webové aplikace, kterým se nezobrazí nic a refresh nepomůže. Podobný osud může potkat jak zákazníka, který čeká na pobočce a nemůže být obsloužen, tak i lunární modul, který nemůže přistát na Měsíci. Ano, je důležité, aby cachování fungovalo správně.
Jak vypadá heapdump
Vraťme se znovu ke všem uživatelům webové aplikace, kterým se nic nezobrazí. Po analýze heapdumpu se dá tento fakt vyjádřit i takto:
http-443-15 thread obtained java.util.concurrent.locks.ReentrantReadWriteLock$NonfairSync's lock & did not release it. Due to that 113 threads are BLOCKED.
Stacktrace vlákna, které nekonečně iteruje:
http-443-15 - priority:6 - threadId:0x49e59800 - nativeId:0x2614 - nativeId (decimal):9748 - state:RUNNABLE stackTrace: java.lang.Thread.State: RUNNABLE at java.util.LinkedHashMap.transfer(Unknown Source) at java.util.HashMap.resize(Unknown Source) at java.util.HashMap.addEntry(Unknown Source) at java.util.LinkedHashMap.addEntry(Unknown Source) at java.util.HashMap.put(Unknown Source)
Vidíme, že mapa provádí resize po přidání prvku a už víme, že tuto akci nikdy nedokončí.
Stacktrace vlákna, které čeká na uvolnění zámku:
http-443-76 - priority:6 - threadId:0x4afd4c00 - nativeId:0x1bec - nativeId (decimal):7148 - state:WAITING stackTrace: java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x190650e0> (a java.util.concurrent.locks.ReentrantReadWriteLock$NonfairSync) at java.util.concurrent.locks.LockSupport.park(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireShared(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireShared(Unknown Source) at java.util.concurrent.locks.ReentrantReadWriteLock$ReadLock.lock(Unknown Source)
Je zřejmé, že vlákno čeká, až získá zámek ke čtení, kterého se ale nedočká.
Původní implementace
Jak byl přístup ke cachi synchronizovaný? Ano, samozřejmě chybně, pojďme se však na implementaci podívat podrobněji.
Třída CacheMap používala zámek ReentrantReadWriteLock, který dovoluje souběžné čtení, ale pouze jeden exkluzivní zápis. K zamykání a odemykání přístupu sloužily metody lockWrite / unlockWrite a dvě analogické pro read.

Zamykání bylo odpovědností kódu, který s cachí pracoval, tedy na „uživatelích“ cache. Než se zamyslíme, jestli je takový návrh vhodný, podívejme se, jak vypadala typická práce s cachí.
V kódu bylo mnoho míst, kde se s cachí pracovalo podle následující šablony, kdy zámek odpovídal prováděné operaci:
try { cache.lockWrite(); cache.put("A", "B"); } finally { cache.unlockWrite(); }
Kód pracující s cachí byl poměrně disciplinovaný, takže ke cachi nikde nepřistupoval bez zamykání:
cache.putAll(otherMap); cache.remove("A");
Na jednom místě nicméně bylo něco podivného:
try { cache.lockRead(); cache.put("A", "B"); } finally { cache.unlockRead(); }
Co je v tomto kódu špatně? Zamyká se pro čtení, ale přitom se provádí zápis. Mnoho vláken najednou mohlo do cache zapisovat a měnit tak její vnitřní strukturu. V cachi dle všeho zeje velká díra.
#encapsulation #loose-coupling
Každá z podporovaných operací nad cachí se zamyká vždy stejně. Přesto je nutné, aby zamykání řešil kód, který s cachí pracuje. Tento aspekt by bylo lepší zapouzdřit přímo v keši.
Nutnost řešit zamykání v kódu, který cach používá, tento kód s implementací cache také velmi úzce svazuje. Pokud bychom chtěli změnit princip zamykání, například výběrem jiného zámku nebo třeba použitím synchronized sekcí, museli bychom aktualizovat i kód používající cache.
Pokud bychom se rozhodli nahradit vlastní implementaci cache nějakou jinou, opět by se taková úprava neobešla bez úprav na všech místech, kde se cache používá.
Refactoring
Všechny popsané problémy s cachí se dají vyřešit poměrně jednoduchým refactoringem. Všechny? Ano, skutečně všechny. Podívejme se na výsledný návrh.
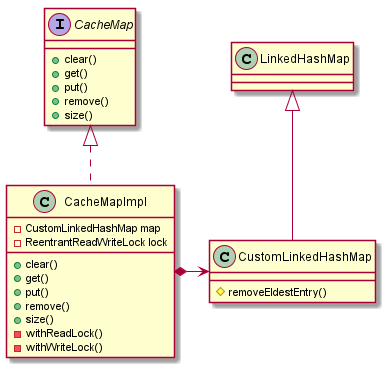
Zkusme si ho opět popsat v řeči principů dobrého objektového návrhu.
#program-to-interface #cohesion
Nově jsme implementaci cache schovali za rozhraní CacheMap. Je jasně vidět, jaké metody cache podporuje, a nenabízí uživatelům cache použít žádné jiné. Rozhraní samozřejmě musí být pěkně okomentované pomocí javadocu. V javadocu se chceme dočíst, jestli je cache thread-safe nebo na jakém principu funguje zamykání. U jednotlivých metod pak vedle popisu funkčnosti očekáváme hlavně popis okrajových podmínek. Co se stane, když dojde k pokusu vložit prvek s již existujícím klíčem? Co se stane, když se pokusíme smazat prvek s neexistujícím klíčem?
Cache je nyní soudržná v tom smyslu, že řeší jen to, co potřebujeme a nic jiného.
#loose-coupling #encapsulation
Synchronizaci přístupu ke cachi a logiku práce se zámkem jsme zapouzdřili ve třídě CacheMapImpl. Public metody implementující rozhraní CacheMap volají private metody withReadLock / withWriteLock a sami tak řeší synchronizaci přístupu k mapě s daty. Uživatelé cache nemají možnost udělat v tom chybu. Ze zamykání se stal implementační detail třídy CacheMapImpl. Přístup k zamykání je možné změnit bez nutnosti úprav kódu, který s cachí pracuje.
#composition-over-inheritance
Od LinkedHashMap jsme zdědili chování, které je pro nás výhodné (tzn. chování mapy a možnost smazat nejstarší prvek), ale pomocí kompozice jsme vystavili pouze takové chování, které chceme uživatelům cache dovolit používat. Používáme mapu, ale nejsme mapa.
Po refactoringu
Příběh má ještě jednu zápletku. K zacyklení docházelo i po refactoringu.
Jak je to možné? Máme lepší návrh, cache soudržnou jako pilíře Karlova mostu, zapouzdřenou synchronizaci, tak kde ještě může být chyba?
Vraťme se k onomu predikovatelnému pořadí iterace prvků mapy, které jsem zmiňoval na začátku. LinkedHashMap rozlišuje dvě strategie pro pořadí, v jakém bude prvky uchovávat. Prvním je „insertion-order“ – pořadí podle toho, jak byly prvky do mapy vkládané. Druhým je „access-order“ – pořadí podle toho, jak se k prvkům mapy přistupovalo. V našem případě byla instance LinkedHashMap-y vytvořená se strategií „access-order“. A kdy se pořadí prvků podle přístupu mění? Ano, při čtení. Při čtení, které mění vnitřní strukturu mapy a které zamykáme pro čtení. Při čtení, kdy get() znamená zároveň remove() a addBefore(header).
Řešením v tomto případě bylo použití strategie „insertion-order“, který je pro nás vyhovující a kdy čtení znamená opravdu čtení.
Závěr
Na konkrétním příkladu implementace cache jsme si ukázali úvahy o pojmech cohesion, louse-coupling, encapsulation a trochu jsme si procvičili i synchronizaci.
Jistě, děláme chyby, ale děláme code review a umíme se z chyb poučit.
Jaké z toho plyne poučení a jaké je doporučení pro implementaci vlastní nemrznoucí cache? Pokud zrovna nevyvíjíte cache jako produkt, sami to raději nezkoušejte a použijte nějakou existující. Nároky běžného projektu na cachování jsou málokdy tak specifické, aby se vlastní implementace vyplatila.
#promo
Zaujalo vás toto téma? Máte jasné názory na dobrý objektový návrh a chcete dělat software kvalitně? Chcete se učit z našich chyb? Přijďte k nám na pohovor.