V mé profesionální kariéře jsem mnohokrát pracoval s datovými sklady. Přestože byly většinou starší, byly skoro vždy strategicky důležitým nástrojem pro infrastrukturu i celou společnost. A jejich nejdůležitější součástí bylo jádro – v něm se totiž integrovala všechna data do stejného modelu, a vytvářela tak jednotný zdroj informací pro další využití. Tato část transformace dat je většinou nejnáročnější na vývoj i vysvětlení klientovi. V dnešní době si všímám různých nástrojů, které umí okamžitě využít shromážděná data bez využití jádra a které jsou dokonce navrženy přímo pro tento způsob transformace. Znamená to, že klasická třístupňová architektura s jádrem je pouhým závanem minulosti a nedá se srovnávat s nejnovějšími designy? Já doufám, že ne, ale uznávám, že co se týče architektury, jsem celkem konzervativní – pojďme se tedy raději podívat na fakta.
Na začátku musím říct, že zkušenosti s datovými sklady jsem získal primárně z BI řešení ve finančním sektoru. To může trochu ovlivnit mou perspektivu, protože tento sektor má konkrétní specifika, například přísnou regulaci. Budování datového skladu pro firmu ve finančním sektoru má vyšší požadavky na datovou kvalitu, spolehlivost a možnost auditovatelnosti dat. Dalším důležitým faktem je, že tyto firmy jsou většinou na trhu už delší dobu, takže jejich BI architektura s jádrem byla postavena už před nějakou dobou, a je tak vysoce nepravděpodobné, že budou otevřeni možnosti úplně předělávat svá DWH řešení od základů. Zaprvé, je samozřejmě těžké prosadit vyšší cenu za velmi podobné výsledky. Zadruhé, když vytvoříte nové BI řešení, musíte se také postarat o to, že nepřijdete o kontinuitu a o data ze stávajícího řešení – to často znamená, že musíte zároveň realizovat nějaký migrační projekt, abyste o nic v procesu přeměny nepřišli. A zatřetí, lidé jsou na staré systémy už zvyklí, nehledě na to, že nové BI řešení může mít požadavky na nové schopnosti, jinak postavené týmy a modifikace v zažitých procesech.
Tak proč se s jádrem vůbec trápit? Jádro je teoreticky nejlepší ve chvíli, když ho chceme použít ke kombinování dat z různých zdrojů na podporu několika BI řešení. Dokud máte jediný datový výstup, jakékoliv transformace a kombinace dat stačí řešit právě na úrovni tohoto výstupu a nějakou přípravnou fázi můžete úplně vyřadit. Totéž platí v případě, kdy máte jen jeden zdroj, který přenáší data do BI řešení – veškerou transformaci můžete provádět na úrovni výstupu. Jakmile však máte několik zdrojů a několik výstupů, je správa vašeho BI řešení mnohem náročnější.
Tradiční řešení s jádrem je v tomto případě tedy rozhodně praktičtější. Představme si, že máme dva zdroje, které generují klientská data. Vyvineme proto jádro, jež je schopné data zprocesovat a následně transformovat. Přidáme kontroly a každé následující řešení můžeme odkazovat k naší elegantní struktuře, která spolehlivě shromažďuje data o klientech na jednom místě. Jádro pak může získávat i kombinovat data z nových zdrojů. Aplikovaný datový model pak motivuje odvozování dalších obchodně relevantních dat, například na klientskou segmentaci. Tento přístup občas vede ke ztrátě metadat na úrovni řádku. Společnosti mají často řádek, který je distribuovaný přes několik relačních tabulek a obsahuje kompletní informaci o klientovi, ale není známo, ze kterého zdroje data pocházejí. Jádro také funguje jako hlavní zdrojový systém – jediný zdroj pravdy pro jakékoliv další využití dat.
Je také dobré zmínit, že existence jádra je užitečná indikace pro regulátory, že máte kvalitní řízení dat a dobré datové procesy. Je totiž velmi náročné postavit fungující řešení s jádrem, a nezaměřit se pořádně na data lineage nebo kvalitu dat. Takže v případě, že vaše BI řešení funguje na bázi jádra, je mnohem jednodušší přesvědčit regulátory, že se vaše společnost stará o kvalitu dat a o další procesy, které regulátory tolik zajímají. Je jednoduché ukázat datový tok a doložit, že všechna vaše BI řešení používají tatáž data.
Nejnovější BI řešení ukazují, že ke zprocesování dat už zkrátka jádro není nezbytné. Stačí jednoduše kombinovat data, která v určitém BI řešení potřebujete. Pokud na následující řešení potřebujete stejná data, stačí původní řešení recyklovat nebo zkopírovat a trochu upravit. Kombinace dat je řešena individuálně v každém výstupu a jádro není potřeba. Dává vám to smysl? Je tento přístup udržitelný?
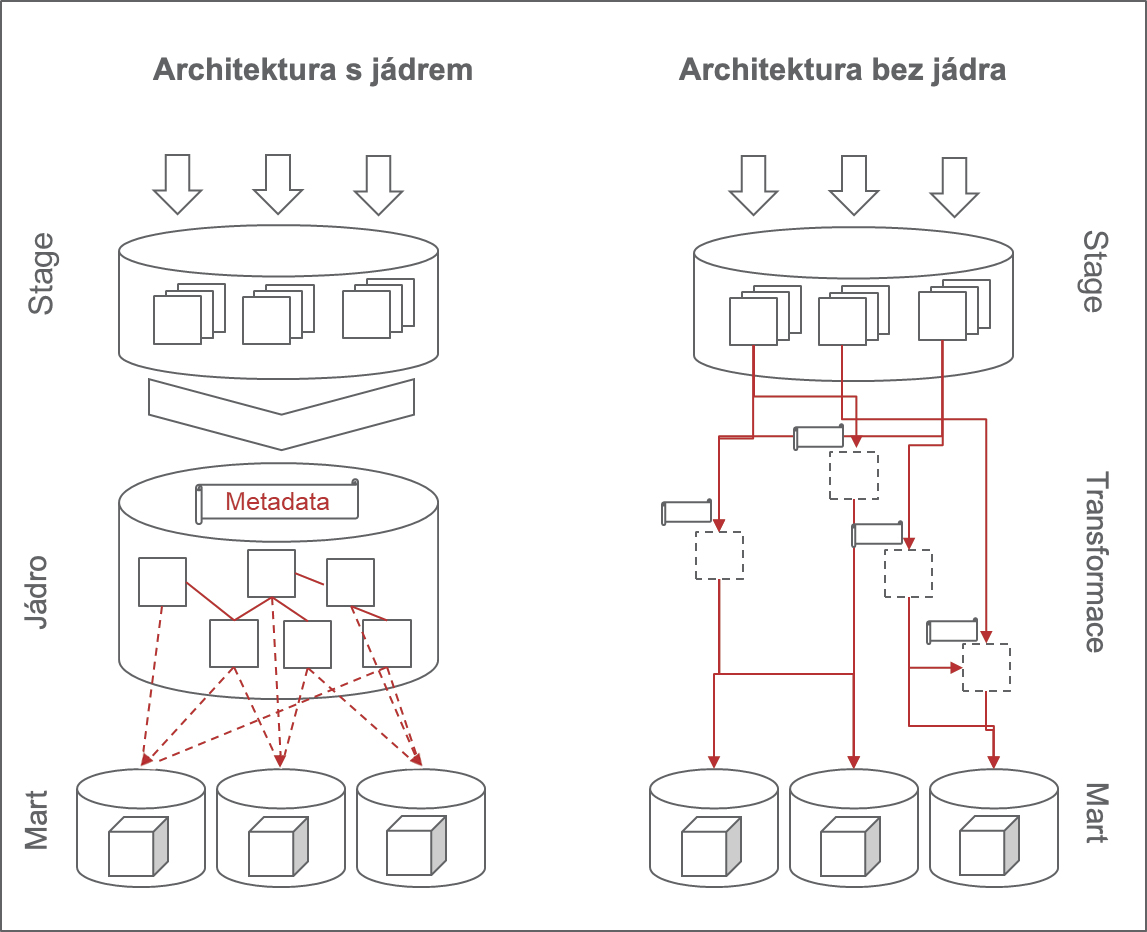
Organizace, technologie a business obecně se za posledních několik let poměrně dramaticky vyvinuly. Organizace začaly preferovat více agilní metodologii (i když se často jednalo o mírně upravenou agilní metodiku), což většinou vedlo k decentralizaci řízení a využití dat. Používání cloudových technologií postupně snížilo potřebu datové deduplikace a optimalizace výkonu. Machine learning a data science měly stejný efekt na strukturu a řízení dat. Většina trhů byla také v posledních několika letech nucena změnit strategii – změna je neoddělitelnou součástí businessového procesu a musí být podporována (mimo jiné i datovým řešením). Úplně jednoduše, když místo jednoho centralizovaného týmu máte deset nezávislých týmů, z nichž každý je odpovědný za E2E dodávky, jedno jádro se může zdát spíše jako překážka a zpomalení celého procesu. Jakmile se nemusíte zaobírat výkonností vašeho BI řešení a náklady na hardware (díky cloudové infrastruktuře), duplikace transformací a datových struktur už nevnímáte jako problém. Když potřebujete vyvinout modulární systém na podporu rychle se měnící poptávky, vývoj stabilního jádra se může zdát krátkodobě ekonomicky neefektivní. Znamená to ale, že v moderní době nemají BI řešení s jádrem na trhu své místo?
Má odpověď zní ne, alespoň zatím ne. Architektura s jádrem je velmi jednoduchý design. Sice je nutné ji pravidelně spravovat, aby jádro fungovalo stabilně a konzistentně, ale za to přináší velmi kvalitní službu. Souhlasím s tím, že některé aspekty architektury s jádrem se musí změnit a upravit tak, aby fungovaly v konkrétním prostředí (např. paralelní zpracování), a jak už jsem psal, je poněkud rigidní. Nabízí však jednotný zdroj jediné pravdy pro všechna návazná BI řešení. Stage-mart řešení také funguje, díky změnám, o kterých píšu výše. Ale aby naše architektura byla udržitelná a jednoduchá pro uživatele, musíme také postavit spolehlivé metadatové řešení na její podporu. Tím myslím, že jestli každý report a výstup je vytvořen z individuálních datových sad kombinovaných z různých zdrojů, tak potřebujeme mít v pozadí metadatové řešení, jež uživatelům umožní vyhledat jednotlivé části řešení, které chtějí znovu využít nebo je potřebují pro vlastní řešení. Uživatelé zkrátka potřebují způsob vyhledávání dat. Místo toho, aby hledali tabulku „klient“ přímo v jádru, měli bychom mít efektivní způsob shromažďování všech klientských tabulek ze všech systémů. Existují řešení, která tento proces nejen podporují, ale také nabízí automatickou klasifikaci dat a machine learning moduly, ale ty musí být přidány k bezjádrovým řešením zvlášť. Proto si myslím, že odstranit jádro a říct uživatelům, aby si na to zvykli, není tak jednoduché. Uživatelé potřebují architekturu, která je podpořena metadatovým řešením.
Souhlasím také s tím, že i architektuře s jádrem by pomohla podpora metadatového řešení, ale jsem přesvědčený, že metadatová řešení jsou mnohem důležitější v BI architektuře bez jádra. Takže pro BI týmy bude nejspíš jednodušší přesvědčit jejich klienty, aby investovali do architektury s jádrem než do masivního metadatového řešení pro podporu jejich uživatelů.
K této myšlence bych se rád vrátil v příštím článku na téma „jak vyměnit jádro za metadatové řešení (a jestli se to vyplatí)“.
Autor: Tomáš Rezek
Information Management Leader