V business reportingu se často setkáváme se situací, kdy je požadavkem sledovat obdobný soubor ukazatelů nad různými kategoriemi. Na výstupu reportu tak dostáváme opakující se sadu sloupců, pouze nad odlišnými metrikami (případně dimenzemi). Následující text porovnává efektivitu a úskalí řešení v závislosti na (de)normalizované formě podkladové tabulky, přičemž v těchto výsledcích vycházím z dosavadních zkušeností získaných na projektu.
Příklad z praxe
Na ukázku uveďme zobecněný příklad z praxe, který sleduje nad různými metrikami vždy dosaženou hodnotu a cíl stanovený pro dané období, poměr těchto hodnot a pořadí procentuálního splnění cíle napříč danou metrikou. Metriky mohou být dále rozřazeny do různých kategorií a například vizuálně rozděleny do více tabulek dle povahy sledovaných ukazatelů (viz obrázek níže). Metriky nemusí být nutně stejného výstupního datového formátu – může jít jak o počty (integer), tak o finanční objemy (decimal) a poměry (percentage), s rozdílným počtem zobrazovaných desetinných míst či odlišnými řádovými převody. Stejně tak můžeme uvažovat i možnost, že v některé metrice může být požadavkem určitý sloupec záměrně nezobrazovat.
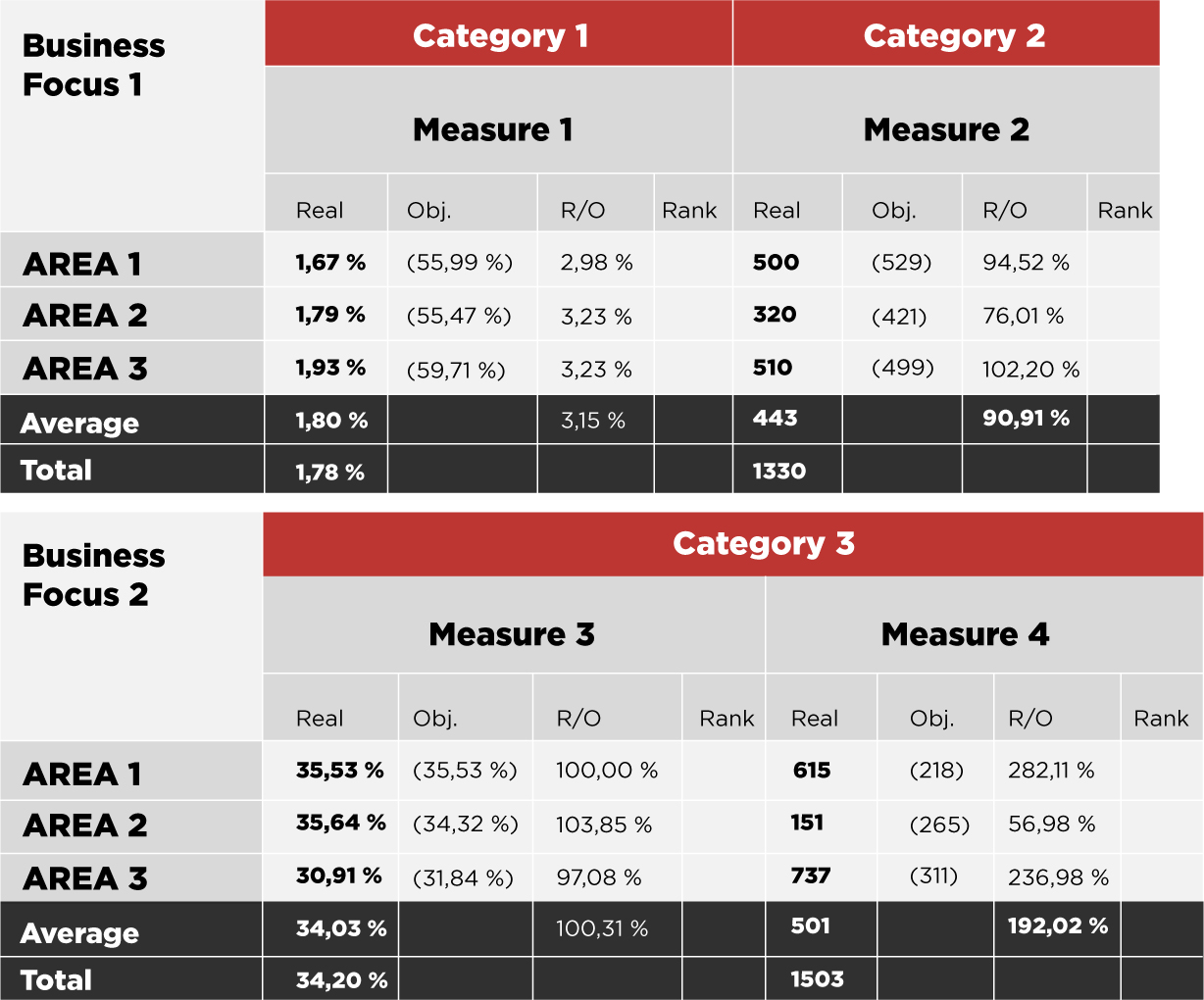
Asi klasickým přímočarým řešením je vytvořit na datové vrstvě agregovanou faktovou tabulku, která pro příslušný dimenzionální klíč uvádí v jednom záznamu soubor všech reportovaných sloupců (nejsou-li dopočítávány na úrovni reportu). V uvedeném případě to pro počet nedimenzionálních sloupců může znamenat až 4× počet všech reportovaných metrik, takže výsledná podkladová tabulka může být značně široká. Navíc, pokud takto modelujeme každý sloupec zvlášť, znamená to nezanedbatelnou manuální práci při vytváření reportu, kdy musíme provést explicitně pojmenování všech sloupců, určení výstupních datových a vizuálních formátů a v samotných reportových položkách (query item) opakovat veškerá dodatečná transformační pravidla. Je zřejmé, že ačkoliv v současné verzi Cognosu existují nástroje, jak si některé kroky ulehčit, stále jsou tyto úpravy časově náročnější. Každé další přidání nové metriky vyžaduje jak rozšíření podkladové tabulky o potřebné sloupce, tak úpravu vlastního reportu.
Při velkém množství sledovaných metrik/dimenzí, případně i častých změnách (jako změny pořadí, přejmenování, nahrazení či přidání sloupce) se může tento způsob implementace stát poměrně neefektivním.
Návrh normalizované formy a její efektivita
Možností, jak redukovat práci při narůstajícím počtu metrik, může být volba normalizování podkladové tabulky, kdy každý řádek tabulky za danou dimenzionální kombinaci sleduje hodnotu jen jedné metrikové položky. Přirozeně tak v tabulce vedle dimenzionálních sloupců definujeme sloupce specifikující metriku a položku (measure_code, item_code) a odpovídající numerickou hodnotu (value_number) uváděnou v univerzálně decimálním typu.
V reportu lze díky takto vytvořené struktuře sestavit jednoduchou tabulku přes dotažení indikátoru položky (measure & item) na pozici sloupců a za sledovanou metriku zvolit numerický sloupec (value_number). Pokud každé položce určíme i její hierarchické zařazení ve formě dalších sloupců, lze jednoduše rozšířit design o kategorizaci jednotlivých metrik, a přidáním informace o požadovaném pořadí (sorting_code) zajistíme jejich stabilní řazení. Při použití Cognos nástroje „repeater“ můžeme určit, co je indikátorem jednotlivých business zaměření, a tím snadno roztřídit výsledky do jednotlivých tabulek.
- Vše implementujeme jednou a modelujeme tím celý soubor metrik současně. To je výhodné jak pro jednotlivá formátování, tak pro definování opakujících se složitějších transformačních pravidel.
- Report na základě tohoto návrhu vytvoří strukturu definovanou datovou vrstvou. Je-li template reportu jednou řádně vytvořen, pak by jakékoliv přidání či odebrání / změna metriky měly vyžadovat úpravy jen datového obsahu. Změny se dynamicky propíšou na reportový výstup.
- Vytvořené „univerzální“ datové struktury lze efektivně znovu použít pro další reporty navrhované v normalizovaném designu.
- Ideálně by každému sloupci reportu měl odpovídat samostatný záznam v podkladové tabulce. To zajistí flexibilitu dodatečných úprav – jako je například potřeba skrytí určitého sloupce.
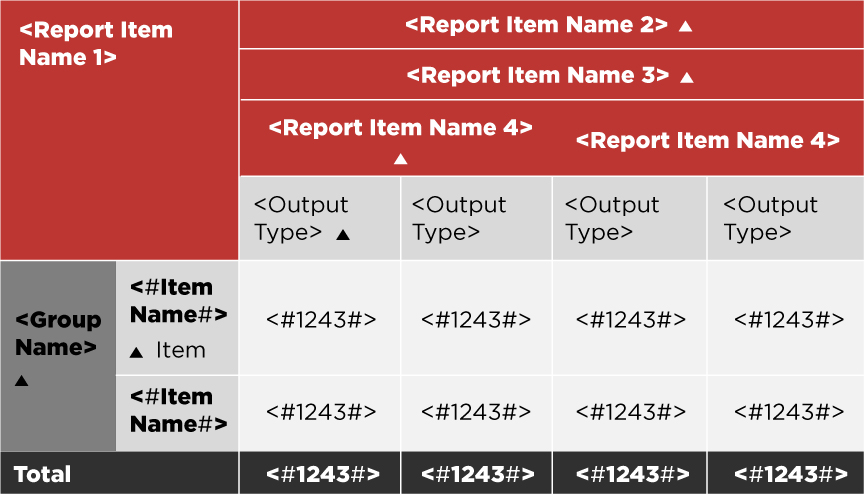
Definování odlišných přístupů v rámci globální definice lze provést jednoduše:
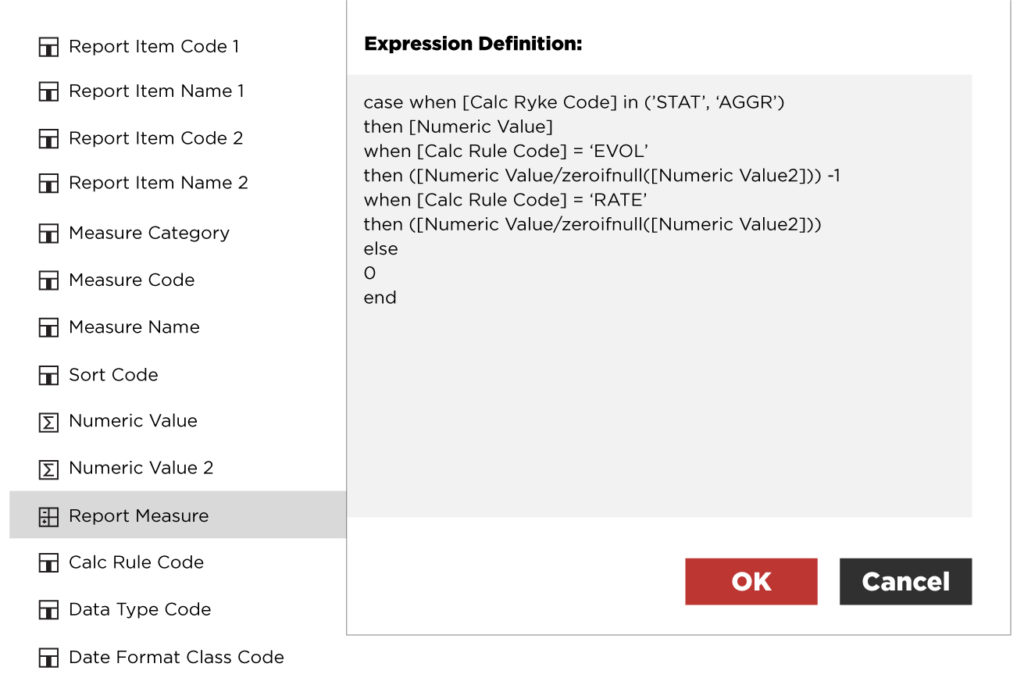
- přizpůsobení výpočtu metrik přes case-podmínky v rámci dané položky (query_item),
- formátování výstupních hodnot a sloupců přes „conditional style“ (dle output type).
Pro specifikaci jednotlivých případů lze sice použít přímo výčet jednotlivých položek, ten ale může být obsáhlý a v závislosti na zvolených kódech identifikátorů nemusí nutně automaticky fungovat pro nově přidávané položky. V praxi se proto osvědčilo přidat další „popisné“ sloupce jako:
- kód datového typu (s možností zahrnutí specifikace počtu desetinných čísel nebo řádů pro výstup, bude-li požadavek různé metriky zobrazovat s různými přesnostmi),
- kód pro povahu výstupního formátu (tučné zvýraznění, barevné odlišení pozitivních/negativních hodnot),
- kód transformačního pravidla (nejsou-li hodnoty přebírané z datové vrstvy bez jakýchkoliv změn),
- příp. další specifické indikátory (např. příznak grafové metriky pro odebírání hodnot pro vizualizaci).

Je patrné, že normalizovaná forma designu není jednoznačným vítězem z pohledu objemu dat. Ačkoliv v ní redukujeme šířku zdrojové faktové tabulky odstraněním explicitních metrikových sloupců, neredukujeme původní dimenzionální část představující primární klíč a naopak přidáváme potřebné identifikátory pro specifikaci sledované metrikové položky a značně zvyšujeme celkový počet záznamů v tabulce. Proto je z praktického hlediska – ať už z hlediska redukce potřebného fyzického místa nebo flexibility úprav na daném reportu – vhodné rozdělit data do dvou datových zdrojů:
- prvním je samotná faktová tabulka, počítaná skriptem, omezená na nutné datové hodnoty (dimenzionální primární klíč vč. identifikace dané metriky, vlastní numerické hodnoty),
- druhým je statická, „manuálně“ udržovaná tabulka, obsahující veškeré řídicí informace, jako jsou reportingové názvy a hierarchické řazení jednotlivých metrik a jim odpovídající definice formátových a výpočetních kódů.
Úskalí normalizovaného designu
Fakt, že dokážeme v normalizovaném designu veškerá pravidla definovat souhrnně, může být nespornou výhodou, zejména právě z hlediska dosud zdůrazňovaného omezení časové náročnosti při vlastní implementaci a drobných změnách designu reportu. Současně se ale tato vlastnost může stát zásadním omezením, kdy přímo musíme být schopni veškeré procesy definovat na globální úrovni. V praxi se na projektu velmi často setkávám se situací, kdy výpočetní výjimky nejsou dané čistě jen technickou podstatou sledované metriky[1], ale kdy je výslovným business požadavkem implementace specifické výjimky na určitém výčtu metrik. Ne všechny reportingové vzory proto mohou být pro takové „centralizované“ řešení vůbec vhodné.
- Musíme mít na paměti, že normalizovaným designem se připravujeme o možnost „kliknout“ fyzicky na „problematickou“ část reportu a individuálně ji za pomoci dalších Cognosových nástrojů a voleb ohnout dle potřeb. Takovým případem bývá v „klasickém“ designu typicky možnost definování vlastního obsahu, kdy v konkrétní buňce definujeme výjimku, aby se nezobrazoval (nepočítal) globální výraz, ale nahradíme výstup jinou explicitně dopočítanou položkou.
- Získat v případě výpočetních výjimek podkladová data ze všech potřebných záznamů může být v normalizovaném formátu značně komplikované. Nelze asi globálně vyhodnotit veškeré možné situace – pokud ale chceme předejít implementačním obtížím, je vhodné rozšířit základní faktovou tabulku tak, aby jeden záznam obsahoval veškeré datové položky, které bude v rámci dodatečných výpočtů na reportové vrstvě nezbytně potřebovat.
V praxi jsem se setkala s business návrhem, kdy v rámci sledovaných numerických výsledků mělo být na výstupu i pár textových sloupců, uvádějících nejčastější důvod vyhodnocení dané metriky (důvod zamítnutí transakce). To například může pro normalizovanou formu představovat zásadní implementační problém. Protože zatímco na datové vrstvě můžeme data snadno rozřadit do numerického a textového (string) sloupce, na reportové úrovni potřebujeme sloučit zpracování dat do společného výstupu, což pochopitelně v případě slučování takto rozdílných datových typů není dost dobře možné. Řešení zavést kvůli jedné výjimce strukturu, kdy pro všechny položky zavedeme oba typy sloupcových výstupů, přičemž však pro většinu z nich zůstane textový sloupec prázdný, a dynamicky pak budeme konkrétní sloupce na výstupu skrývat, se nezdá úplně jako efektivní přístup. Z mého hlediska jde však v tomto případě spíše o celkově špatný samotný návrh reportu než o nedostatek normalizovaného designu. Uvedený příklad textové informace představuje de facto jen další doplňkovou dimenzi pro danou metriku a z podstaty věci by se proto neměla zařazovat do metrikové části tabulky. Zároveň takový výstup nemusí mít vůbec vhodnou vypovídající hodnotu pro business. Zejména pokud uvážíme, že se na reportovanou hodnotu může dostat zcela obecná informace (typu „neklasifikovaný“ důvod) a chybí porovnání s ostatními kategoriemi dané metriky, kdy další (nezobrazené) hodnoty mohou být zcela konkrétní (a tedy podnětné k dalším analýzám a hledání business řešení) a přitom co do četnosti výskytu srovnatelně závažné. Z analytického hlediska se tedy v tomto případě, bez ohledu na zvolený způsob designu reportu, zdá třeba mnohem vhodnější přesunout „dimenzionální“ informaci do vhodně navržené grafové vizualizace.
V neposlední řadě může být rozhodovacím aspektem při plánování designu reportu nepochybně i časový plán vývoje a rozložení implementačních kapacit.
- Normalizovaný design reportu je poměrně citlivý na koordinaci vývoje. Protože je design zásadním způsobem závislý na datové části, a to mnohem citelněji než explicitně modelovaný report, je normalizovaný přístup vhodný jen v případě, že povaha projektu umožňuje sekvenční načasování vývoje datové a reportové vrstvy, s případným závěrečným doladěním obou vrstev na základě testování.
Závěr
Pokud jde o celkové zhodnocení efektivity (de)normalizovaného designu, určitě nelze jednoznačně prosazovat jeden nebo druhý přístup a na základě zkušeností nelze tvrdit, že by byl normalizovaný design něčím naprosto „nepřekonatelným“ a vždy vedl nejkratší cestou k cíli. Oba způsoby mohou pomoci vhodně řešit odlišnou oblast implementace a je tedy hlavně na dobrém analytickém zvážení, jaký je očekávaný stávající design reportu i jeho předpokládaný rozvoj. Pokud zvažujeme normalizovaný designu reportu v Cognosu, určitě doporučuji vždy:
- Provést podrobnou revizi všech designových a výpočetních výjimek a rozmyslet si možnost jejich efektivního vyřešení. Případně, nabízí-li se taková možnost, přizpůsobit finální report a eliminovat v něm přítomné výjimky.
- V případě, že nejsme schopni zajistit přítomnost veškerých potřebných dat v jednom záznamu, pak je více než vhodné provést zjednodušenou simulaci vývoje ještě v úvodu analýzy před konkrétním rozpracováním funkční specifikace, abychom si ověřili realizovatelnost navrhovaného řešení. Ohýbání problému „za každou cenu“ se totiž může později ukázat jako naprosto neefektivní – jak ve smyslu „těžkopádnosti“ implementace, s možným ovlivněním výsledného výkonu, tak v náročnosti samotné realizace, jež může nakonec převyšovat čas, který měl být volbou normalizovaného designu ušetřen.
Autorka: Martina Válková
IT Consultant
[1] Příkladem je výpočet celkových hodnot (Total), kdy je nutné „poměrové“ metriky počítat explicitně jako podíl sumárních čitatelů a jmenovatelů všech zahrnutých položek, nikoliv jako prostý součet (viz metrika 1 a 3 na úvodním obrázku článku).