Část profinitího Data Science týmu v období parných letních měsíců vybočila z analyzování dat českých bank a po hlavě se vrhla do Kaggle soutěže, kde mezi sebou soutěží světové špičky ve svém řemesle.
Co je vlastně Kaggle a jak se zde soutěží?
Kaggle je největší světová online Data Science platforma, vlastněná firmou Google. Na stránce lze nalézt kromě různorodých soutěží v prediktivním modelování také veřejné datasety, portál pro vzdělávání, diskuze nad nejnovějšími články, a mnoho dalšího.
Typický průběh soutěže vypadá tak, že firma poskytne svá anonymizovaná data, popíše, co chce z dat predikovat, v jakém formátu a exaktně stanoví vyhodnocující metriku, ze které se určí pořadí odevzdaných řešení. Pak už mají soutěžící několikaměsíční volné pole působnosti, než přijde finální deadline a vyhlášení vítězů.
Mezi nejzvučnější instituce, které zde v minulosti měly vypsanou veřejnou soutěž, se řadí např. Google, Airbus, ministerstvo vnitřní bezpečnosti USA, Intel, Mercedes Benz, Microsoft, CERN a tak dále.
Samozřejmě se naskýtá otázka, proč právě takovéto firmy vypíší veřejnou soutěž v prediktivním modelování, když bez pochyby mají několik špičkových AI týmů. Odpověď je relativně jednoduchá. Malé zlepšení síly prediktivního modelu (nebo myšlenka, jak toto zlepšení provést) může být pro firmu naprosto klíčové a šance, že se to povede některému z Kaggle týmů, je veliká.Naše soutěž – předpovídání solventnosti klienta, který si bere úvěr.
Soutěž, které jsme se zúčastnili, vypsala firma Home Credit a poskytla data z jedné ze zemí, kde působí. K dispozici bylo přes 300 tisíc údajů o poskytnutých půjčkách a následně binární proměnná, která indikovala, zda daná půjčka byla splacena dle smluveného kalendáře, či nikoliv. Dále byla k dispozici množina s přibližně 50 000 půjčkami, o kterých jsme měli stejné informace, nicméně už bez znalosti toho, zda byla splácena včas. Tento údaj byl právě cílem predikce a vyhrál tedy tým, který tuto množinu co nejpřesněji ohodnotil. Home Credit vypsal štědrou odměnu pro vítěze ve výši 35 000$ za 1. místo, 25 000$ za 2. místo a 10 000$ za 3. místo. Čas na vypracování byly přesně 3 měsíce. Soutěže jsme se zúčastnili z prostého důvodu – data jsou z finanční domény, která je nám vlastní, a v případě vysokého umístění možnost navázání spolupráce s Home Creditem, či nabízení našeho řešení do dalších bank.
Jak se vyvíjelo naše řešení v čase?
Poskytnutých údajů o každém úvěru bylo opravdu hodně (dokonce i takové absurdity, jako kolik výtahů a pater má dům klienta nebo z jakého je materiálu), což přinášelo velký prostor pro vytváření vlastních inovativních příznaků, které by mohly korelovat s onou solventností. První přístup tedy byl, že se každý snažil urvat výsledek sám „zlatým“ nápadem. Po dvou až třech týdnech jsme pochopili, že se nám bohužel nic takového nepodaří, a že vypovídající schopnost dat je omezená. Také jsme se museli smířit s tím, že vítězné příčky nejspíše atakovat nebudeme.
Úlohu jsme si tedy rozdělili. Každý z nás prozkoumával jiné sady poskytnutých příznaků a vytvářel nové, sdíleli jsme mezi sebou kód.
Například při detailnější exploraci dat jsme po vykreslení bodového grafu, kde na jedné ose bylo stáří klienta a na druhé ose bylo stáří průkazu totožnosti, dostali následující obrázek:
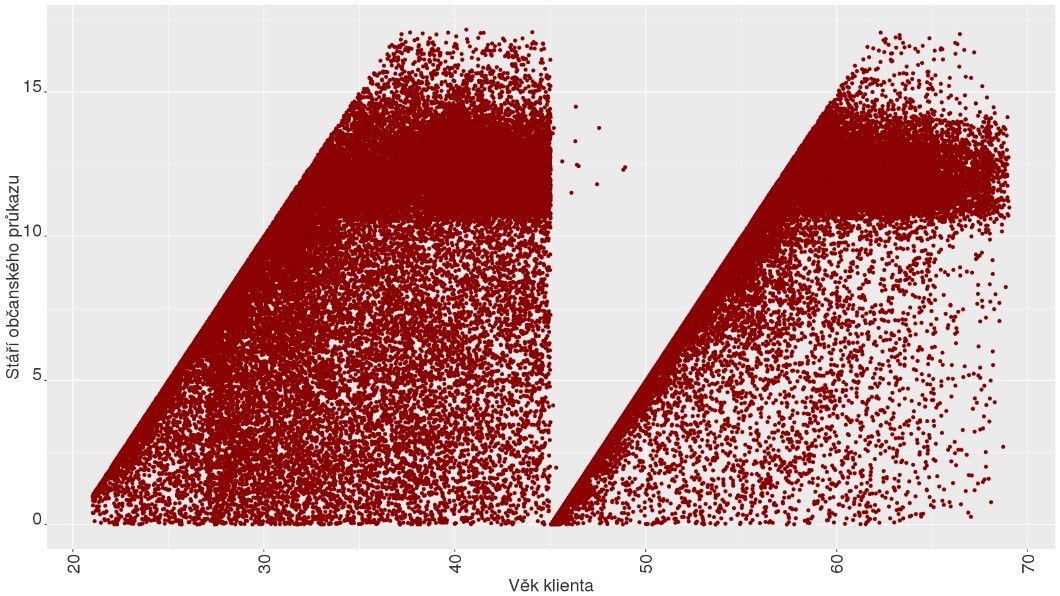
Z grafu je vidět, že nový průkaz dostane občan dané země ve 20 letech a ve 45 letech evidentně dochází k jeho výměně. Po krátkém pátrání jsme zjistili, že tento proces přesně odpovídá na ruský systém přidělování mezinárodního pasu. Dvě nejhustěji zastoupené diagonály se vyznačují očekávaným chováním, tj. se zvyšujícím se věkem klienta rovnoměrně roste stáří průkazu. Dále jsme se dočetli, že kolem roku 2004 probíhala hromadná, nikoliv však absolutně povinná výměna, což odpovídá početnému zastoupení případů, kdy je průkaz starý 10 až 14 let. Informace, že data opravdu pochází z ruského trhu, nám přinesly cenné podklady, které jsme využívali v dalších analýzách.
Dále jsme nastudovali a začali používat nejnovější algoritmy strojového učení, založené na rozhodovacích stromech, které jsme ještě dále zkoušeli optimalizovat za pomocí služby Amazon Web Services a krůček po krůčku se naše řešení zlepšovalo.
Tato fáze trvala zhruba měsíc a půl a naše umístění se drželo na hraně nejlepších 10 % ze všech zúčastněných.
Poté následovala poslední fáze, která byla spíše skeptická. Každý náš nápad, ať už jsme si mysleli, že je sebelepší, přinesl buď žádné, nebo absolutně nepatrné zlepšení, což bylo při dostatečném opakování poněkud demotivující. Ve snažení jsme nicméně vytrvali až do 29. srpna, kdy byl deadline. Pak už zbývalo jen vybrat 2 řešení, o kterých jsme si mysleli, že jsou nejlepší a odeslat je k finálnímu ohodnocení, kde byly naše predikce porovnány se skutečností.
No a výsledek? Umístění v nejlepších 3.6% výrazně vylepšilo naše průběžné umístění. Soutěže se zúčastnilo více než 7000 týmů, které se skládaly ze zhruba 9500 uživatelů. Tyto počty udělaly ze soutěže dosud největší, která se na Kagglu doposud odehrála. Nám účast přinesla kromě velmi nadprůměrného umístění také neocenitelné zkušenosti, které se budou jistě hodit na dalších projektech. Možnost zúčastnit se naplno takovéto soutěže (ve smyslu investovaného času), porovnat se se světovou špičkou a učit se od ní prostřednictvím veřejných diskuzí a kernelů se nenaskýtá každý den.