Monolity je zpočátku snadné vyvinout, nasadit i škálovat, ale výhody, které nám dovolily rychlý start, nás s rostoucí velikostí aplikace mohou začít výrazně brzdit. Není lehké vyznat se v rozsáhlých zdrojácích. Často neexistují jasné hranice modulů a modularita se někdy zbortí. Právě postupná degradace kvality kódu monolitů byla jedním z důvodů pro vznik mikroslužeb. Je ale cesta mikroslužeb jedinou možnou? Není možné psát monolity lépe?
Kód tradičně organizujeme po vrstvách. Controllery, služby, repository, … znáte to. Je vrstvení anti-pattern nebo rozumný způsob, jak psát Java aplikace? Na jednoduchém příkladu monolitické aplikace – měnové burzy – porovnáme vrstvení s vhodnějším způsobem organizace kódu po komponentách. Docílíme tak stylu kódování, který se dá nazvat architektonicky evidentním.
Burza
Představme si primitivní měnovou burzu. Její funkcionalitu pro potřeby našeho článku zjednodušíme na práci s uživateli, měnami a požadavky na nákup nebo prodej.
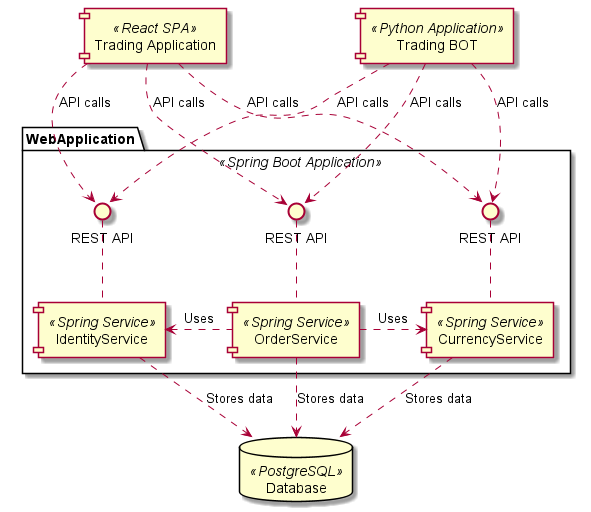
Na diagramu architektury vidíme, že burza je implementovaná s využitím frameworku Spring Boot jako jeden monolit. Data se ukládají jako relace v PostgreSQL databázi. K burzovnímu API přistupují dva klienti – SPA pro práci uživatelů napsaná v Reactu a aplikace pro robotické obchodování napsaná v Pythonu.
Funkcionalita je implementovaná třemi komponentami – službami IdentityService (práce s uživateli), CurrencyService (práce s měnami) a OrderService (nákup a prodej). OrderService používá IdentityService a CurrencyService. Všechny služby ukládají data do databáze. Žádné jiné závislosti v diagramu nejsou.
Architektura obvykle předpokládá, že kód je skutečně rozdělený do navržených komponent a že jsou mezi nimi právě a pouze ty závislosti, které architektura dovoluje. Právě a pouze ty a žádné jiné? Co asi uvidíme v kódu Spring Boot aplikace? Bude to jednoznačně odpovídat architektuře? Najdeme tam naše komponenty?
Horizontální vrstvy
Je obvyklé, že kód v Javě organizujeme po vrstvách. Naše aplikace má vrstvy tři – api, služby a repository. Každá vrstva je mapovaná do jedné Java package.

Proč vlastně zavádíme vrstvy? Často jenom proto, že se to tak dělá. Protože funguje cargo cult, kdy některé vzory opakujeme, aniž bychom přesně věděli proč.
Pro použití vrstev ale existují i dobré argumenty. Martin Fowler říká, že vrstvy jsou efektivním způsobem modularizace. Za jejich největší výhodu považuje možnost soustředit se poměrně nezávisle na koncepty, které implementují.

Modularizace formou vrstev dovoluje znovupoužít kód z jiných vrstev – např. službu IdentityService používají controllery IdentityController a OrderController. Jistě, možnost znovupoužít kód z jiných tříd je přece úplnou samozřejmostí, ale je dobré si uvědomit, že jsme jí dosáhli díky vrstvám. Další zřejmou výhodou je možnost použít mock implementace tříd z jiné vrstvy v testech – např. testy pro OrderController mohou pracovat s mocky služeb OrderService a IdentityService.
Co naše architektura? Je v implementaci vidět? Typy, které k sobě logicky patří – např. OrderController, OrderService(Impl) a OrderRepository – jsou každý umístěný v jiné Java package. Komponenty architektury se v implementaci rozplynuly do třech vrstev.
Co vrstvy a závislosti? Teorie říká, že závislosti mezi vrstvami by měly vést pouze směrem od vyšších vrstev k nižším. V našem příkladu mohou controllery používat služby, ale neměly by přímo přistupovat k repository rozhraním. Dlouhou dobu se nám to může dařit, ale stále hrozí, že s rozvojem aplikace přijde chvíle, kdy to platit přestane. Vrstvy mapujeme na Java packages a závislosti mezi vrstvami tak musí pracovat s public typy. Uvnitř jednotlivých packages se navíc může dít cokoliv. Vrstvy jsou velmi úzce provázané, protože změna jedné komponenty architektury většinou znamená nutnost měnit typy ve třech vrstvách / Java packages. Vzniku nechtěných závislostí tak brání pouze naše disciplína a možná snaha o průběžné code review.
Jedním z důvodů, proč často degraduje kvalita kódu u monolitů, jsou právě nekontrolované závislosti. Jak říká Simon Brown, každý public typ je potenciální budoucí závislostí.

S rozvojem aplikace se vrstvy zvětšují a nastává tedy potřeba další modularizace. Opět si půjčím myšlenku Martina Fowlera.

Jak můžeme kód organizovat lépe než po vrstvách?
Vertikální komponenty
Architektura definuje tři komponenty a jejich API – IdentityService, OrderService a CurrencyService. Proč tedy nemít kód organizovaný do packages podle nich?
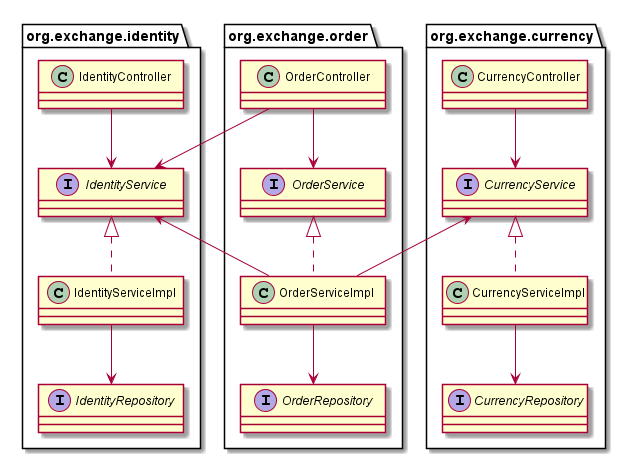
Pro každou komponentu nyní jednoznačně najdeme package, která ji implementuje. Z diagramu architektury jsme se do class diagramu implementace vlastně dostali zazoomováním na větší úroveň detailu. Simon Brown tento přístup k organizaci kódu nazývá architektonicky evidentním. Koncept zoomování nad vizualizací architektury pěkně popisuje ve svém C4 modelu.
Zastavme se u modifikátoru přístupu public. Je další tradicí mít všechny typy public. Ale proč vlastně? Přiznejme si, že o modifikátoru public většinou rozhodne šablona v IDE a dál to neřešíme. Už jednou jsme tvrdili, že každý public typ je potenciální budoucí závislostí. Které typy opravdu musí byt public? Jen rozhraní služby. Jeho implementace, repository interface i controller mohou být package private. Jediné, na čem mohou komponenty z ostatních packages záviset, je tak naše rozhraní a typy, které se v něm vyskytují.
Vrstvy jsou v implementaci přítomné pořád, ale stal se z nich pouhý implementační detail jednotlivých komponent. Java package už nemá jenom roli organizace kódu, ale spolu s modifikátory přístupu nám garantuje i jeho zapouzdření. Každá komponenta publikuje pouze svoje public rozhraní. Správa závislostí mezi komponentami se tak stala jednodušší a přehlednější.
Má to nějaký dopad na fungování naší Spring Boot aplikace? Component scanning funguje i nad package private typy. Spring Data rovněž umí implementovat i package private repository.
A co unit testy? Pokud je umístíme do stejné package jako testované třídy, není s přístupem problém. Pokud dáváme přednost integračním testům, které přistupují k rozhraní služby a používají její reálné závislosti včetně repository, provede za nás inicializaci Spring.
Co když bude package příliš velká? Pak je samozřejmě na místě další rozdělení, které si vynutí další public typy. Mapování komponenty na jednu package a její subpackages má smysl dál. Omezení architektury jsme neporušili, náš kód je stále architektonicky evidentní, ale bohužel jsme ztratili výhodu zapouzdřené implementace komponenty. Řešením mohou být Java 9 moduly nebo například testy architektury s knihovnou ArchUnit. V každém případě musíme začít rozlišovat mezi public a published typy, tedy tím, co musí být „vidět“ a tím, co skutečně chceme publikovat.
Pokud vezmeme předchozí dva diagramy – strukturu po vrstvách a po komponentách – a odstraníme z nich packages, dostaneme naprosto identické diagramy.
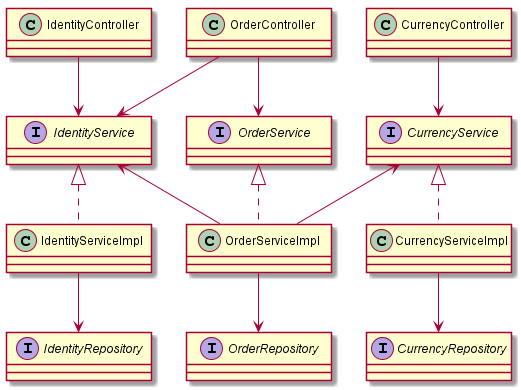
Náš záměr implementovat komponenty ve třech vrstvách je v obou případech úplně stejný. Skutečně jsme porovnávali pouze rozdělení implementace do packages. Organizací kódu podle komponent docílíme lepšího zapouzdření, kdy můžeme publikovat pouze nezbytně nutné rozhraní služeb a všechno ostatní skrýt jako implementační detail.
Shrnutí
- Obrázky architektury často neodpovídají tomu, co je obsažené v kódu
- Vrstvy jsou dobré, ale raději jako implementační detail komponent
- Rozdělením kódu do packages podle komponent jsme si ponechali výhody vrstev a získali architektonicky evidentní kód
- Šetřete s modifikátorem přístupu public
Autor: Tomáš Piňos
Odkazy
Martin Fowler – PresentationDomainDataLayering – https://martinfowler.com/bliki/PresentationDomainDataLayering.html
Simon Brown – An architecturally-evident coding style – https://www.codingthearchitecture.com/2014/06/01/an_architecturally_evident_coding_style.html
Simon Brown – Modular Monoliths – https://www.youtube.com/watch?v=5OjqD-ow8GE
Simon Brown – C4 Model – https://c4model.com
Chris Richardson – Monolithic Architecture – https://microservices.io/patterns/monolithic.html
Steve McConnell – Cargo Cult Software Engineering – https://stevemcconnell.com/articles/cargo-cult-software-engineering
Unit test your Java architecture – https://www.archunit.org