Čerství absolventi čekají, že vytvoří nový doporučovací systém nebo algoritmus řazení výsledků vyhledávání. Ve skutečnosti musejí řešit problémy s chybějícími daty, škálovatelností a integrací. A navíc si ještě musejí osvojit procesy společnosti nebo vytvořit nové. Že to v pracovním prostředí chodí jinak než ve škole, se dá čekat, na poli datových věd ale číhají jedinečné výzvy. V tomto příspěvku chci popsat pár věcí, které jsem se za poslední roky naučil.
Dělám to správně?
Jedním ze zásadních rozdílů mezi školním a pracovním prostředím je míra nejistoty. Když řešíte problém ve škole nebo v kurzu, nejspíš vám předestřou jasný záměr a pokyny, jak dosáhnout cíle. Tady máte datovou sadu. Tady máte metriku. Tohle je optimální řešení. Použijte tyhle a tyhle metody.
Budíček! Vítejte v novém světě aplikovaných datových věd. Nevíte, která metrika je pro daný problém nejvhodnější. Nevíte, který algoritmus je nejlepší. Nevíte, jaké je nejlepší možné skóre. Dobré na tom je, že to neví nikdo.
Agilní metodologie představuje šikovný způsob, jak si s takovou nejistotou poradit. Pomůže vám a vašemu týmu reagovat na změny za přijatelně dlouhou dobu. Měli byste pravidelně přehodnocovat své cíle a aktualizovat je na základě nových informací.
Věříte svým datům?
Ve vědecké praxi jsem se ze všeho nejdřív naučil, že datům se nedá slepě věřit. Tuhle chybu člověk udělá strašně snadno. Kurzy zaměřené na strojové učení a datové vědy se vesměs soustředí na všeobecně známé problémy ohledně definičního oboru a standardně využívané datové sady. Máme datovou sadu Titanic pro klasifikaci, datovou sadu cen nemovitostí pro regresi a MNIST pro neuronové sítě. Srovnejte je s datovou sadou ve své společnosti.
Tohle je jen pár problémů, se kterými jsem se setkal minulý týden.
- Uživatelsky generovaná data. To je obří chaos. Lidé mají úžasnou schopnost dát jedné věci spoustu různých názvů. Pochopit smysl takových částečně strukturovaných dat představuje nesmírně časově náročný proces. A je to nuda. Já tu jsem přece od toho, abych předával poznatky a ne abych analyzoval, jak se dá hláskovat slovo „účet“ na padesát způsobů. Množství manuální práce se podceňuje.
- Data tam prostě nejsou. Nejhorší data jsou taková, která nemáte. V softwaru může být chyba nebo podivné chování produkující data, která si žádají zvláštní pozornost. Zrušená transakce se například objevuje jako běžná transakce, ale s cenou zadanou jako záporné číslo. Dalším příkladem může být systém zaznamenávání protokolu, který systematicky vypouští „zanedbatelné“ události, protože nesouvisejí s účtováním.
- Data jsou nesouvislá. V nejnovější verzi byl změněn způsob, jakým vaše společnost identifikuje uživatele, nebo byla zavedena změna mapy webu nebo datového kanálu. A teď před sebou máte obtížnou otázku: Co udělat se starými daty? Někdy můžete stará data odstranit, jindy musíte ručně namapovat staré události na nové.
Přistupujte k analýze dat s obrovskou pečlivostí. Zapište a ověřte si veškeré předpoklady ohledně dat u zainteresovaných osob v podniku. Mějte na paměti, že data nejsou přesným znázorněním skutečného světa, ale jen jeho přibližným odhadem.
Vaše práce je nedokončená, dokud není použitelná
Nikdo: Potřebuji luxusní model neuronové sítě, který je co možná nejpřesnější.
Model s vysoce výkonnou metrikou je dobrý začátek, ale tím to nekončí. Teď je třeba vytvořit spolehlivý datový kanál. Konečný výsledek může mít mnoho podob:
- Denně vytvářená tabulka v databázi.
- Panel s predikcemi na příští týden.
- Nebo aplikace na odhalování podvodů se zpracováním streamu v reálném čase.
Bez ohledu na to, jaké řešení je potřeba, vyžaduje to značné technické dovednosti a úsilí. Na řadu přicházejí věci jako Git, testování částí a čitelnost kódu. Více si k tomuto tématu můžete přečíst tady. Inženýři společnosti Google odhadují, že základní kód strojového učení tvoří jen 5 % veškerého napsaného kódu.
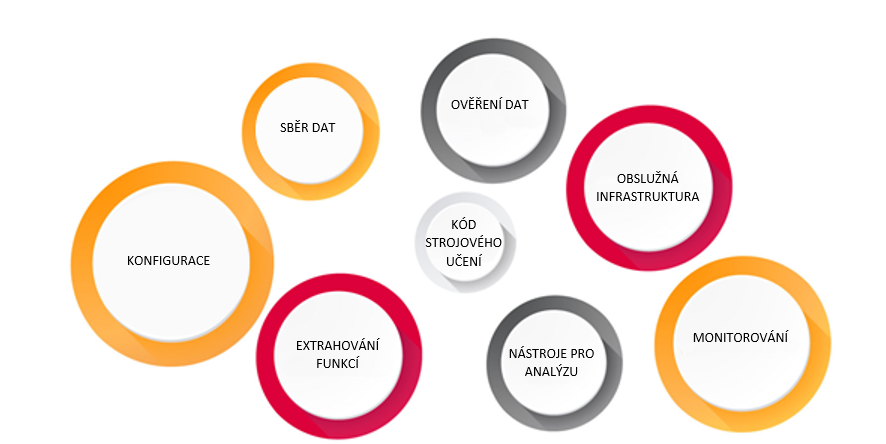
Rozhodně věnujte určitý čas studiu základů softwarového inženýrství a zahrňte do svého vývojového procesu revize kódu.
Na závěr ještě několik rad.
- Buďte pragmatičtí. Najali vás, abyste řešili úlohy související s daty. Tímhle své společnosti pomáháte. Jednoduchý model fungující v provozu dnes je lepší než luxusní model fungující v laboratorním prostředí ode dneška za měsíc.
- Intenzivně svůj kód testujte. Jeden den testování navíc může v budoucnu ušetřit vám i vaší společnosti spoustu času i peněz. Najděte si na platformě Google Developers kurz o testování modelů strojového učení.
- Vzchopte se a přidejte. Nad zkoumáním a čištěním dat strávíte víc času, než čekáte.
Autor: Sergii Stamenov
Data Science Consultant