Digital Transformation je kryptický termín, pod kterým si různí lidé představují různé věci. Většinou se shodnou, že Digital Transformation je spojena s novými technologiemi a s jejich využitím pro nové typy služeb, produktů a procesů.
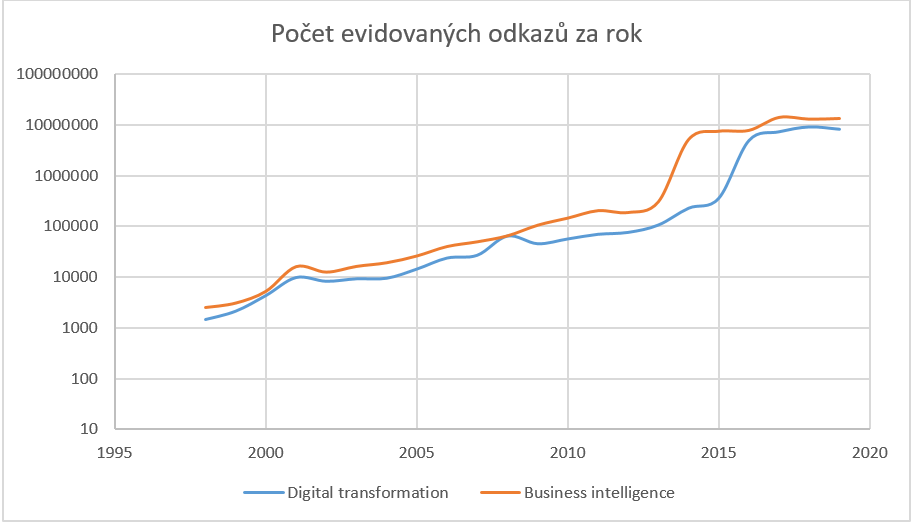
Samotný termín digitální transformace má dlouhou historii. Na tento termín poskytuje Google 1450 odkazů z roku 1998. To je rok založení Googlu coby ikonického příkladu Digital Transformation. Google již eviduje 4320 takových odkazů za rok 2000 a 56 800 odkazů za rok 2010. A za rok 2018 už eviduje 9 300 000 takových odkazů, což je o 1 840 000 více než za rok 2017.
Dá se očekávat, že historie vlivu Digital Transformation na IT bude podobná jako historie Business Inteligence (BI), akorát bude posunutá o jednu nebo dvě dekády. U BI trvalo přes deset let, než se ustálilo povědomí, co může Business Inteligence přinést a co znamená z pohledu Data Managementu.
Do datové architektury přinesla Business Inteligence jasný požadavek na jednotnou integraci dat celé organizace. Tento požadavek vedl k vytvoření datových skladů s datovým modelem orientovaným podle business domén organizace, popřípadě k vytvoření skupiny specificky orientovaných operativních datových skladů pro specifické business požadavky. Z hlediska datových kompetencí a služeb vedla Business Inteligence k rozvoji datové kvality, integraci dat a Master Data Managementu. Z pohledu řízení organizace umožnila mít každé rozhodnutí podpořeno potřebnými aktuálními daty v uživatelsky přívětivých reportech. Z pohledu řízení dat prokázala důležitost metadat, jejich zpracování a analýz. A na závěr z pohledu technologií přinesla ETL procesy, datové servery umožňující efektivní dotazy nad velkým objemem dat a také například OLAP databáze – řešení pro předem definované analýzy.
Jaké budou dopady Digital Transformation na IT, zatím není jasné. Nicméně její vliv na datovou architekturu se již začíná rýsovat. Ukazuje se, že nové typy služeb a produktů jsou postaveny na zpracování velkého množství dat z mnoha zdrojů, které je nezvládnutelné zpracovat v klasických datových skladech postavených na relačních databázích. Relační databáze jsou jednak optimalizovány na zpracování SQL dotazů, nikoliv složitých výpočtů prediktivních algoritmů, analýzy textů nebo rozpoznávání hlasu a obrazu, a jednak jsou pro velké množství dat velmi drahým datovým úložištěm. A nejde zde jenom o cenu uložení, ale také o cenu procesů zařazení dat do datového skladu, kdy se vyžaduje přesný popis dat, vysoká datová kvalita a schopnost integrace s ostatními doménami v datovém skladu.
Digital Transformation je spojena s novými typy analýz, s využitím umělé inteligence, s novými typy komunikace se zákazníky a s novými typy produktů založenými přímo na zákaznických datech.
A proto vyžaduje nový přístup k uložení a zpracování dat ve formě levnějšího datového úložiště se schopností škálovatelného výpočetního výkonu – Data Lake. Architektura typického Data Lake je na obrázku 2.
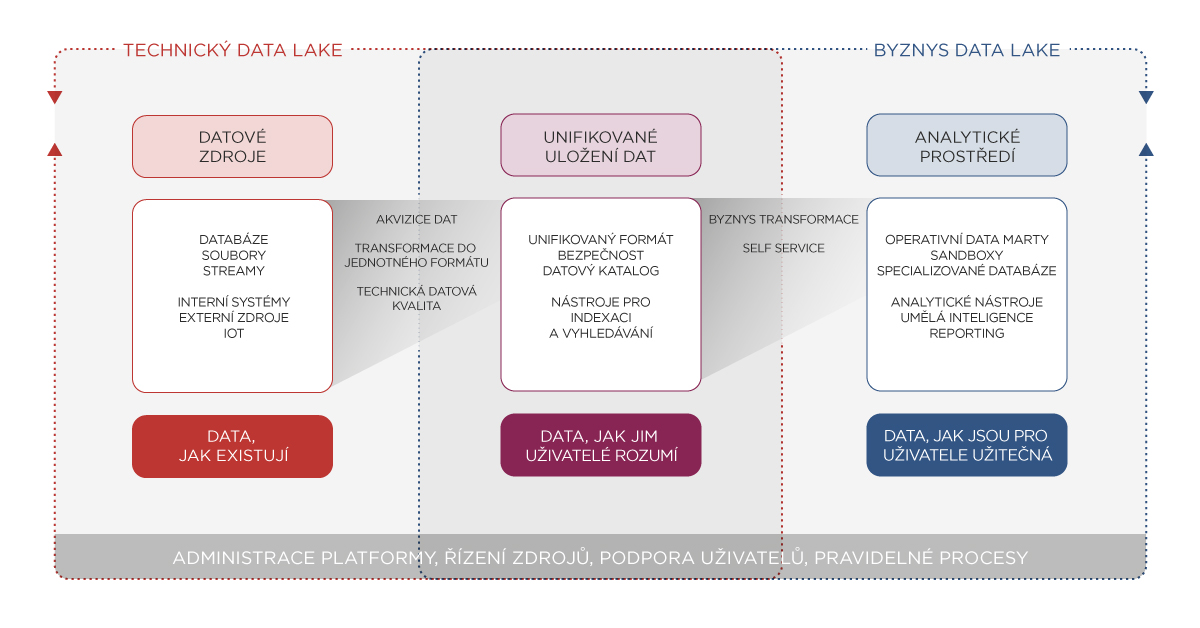
Ale stejně tak jako samotné pořízení výkonného serveru neřeší požadavky BI, tak ani samotné pořízení Data Lake prostředí neřeší požadavky Digital Transformation. Aby měl Data Lake skutečný business přínos, je třeba vytvořit a rozvíjet potřebné funkce a kompetence. Zde je seznam těch, které považuji za nejdůležitější:
- Schopnost rychlého zařazení dat do Data Lake. Přidání nového datového souboru musí být po technické i procesní stránce rychlé a jednoduché, ať už se jedná o pravidelný load dat, jednorázové nahrání nebo zapojení datového streamu.
- Uložení dat společně se strukturou. Datové formáty jako AVRO nebo PARQUET ukládají datovou strukturu společně s daty a umožňují ukládat i složitější struktury než pouze relační tabulky.
- Schopnost vyhledávat data. Je důležité, aby vyhledávání dat nebylo založené pouze na datovém katalogu. V současnosti technologie umožňují takovou indexaci dat, že je možné odpovídat na otázky typu: „Kde všude se v Data Lake nachází informace o produktu KP12345?“ nebo „Kde všude se nachází telefonní čísla?“.
- Schopnost použití různých výpočetních komponent. Jak se zvětšuje počet uživatelů pracujících s daty, zvětšuje se i počet nástrojů pro zpracování dat, které uživatelé vyžadují. Data Lake musí mít schopnost napojit se nejen na standardní reportingové nástroje, ale také na různé nástroje umělé inteligence a strojového učení. To je často spojené s nutností přenášet data do speciálních úložišť těchto systémů.
- Ukazuje se, že sandboxing a self-service jsou kritické funkce Data Lake řešení. Čím dál více uživatelů je schopných s daty pracovat samostatně a vytvořit si svoje vlastní řešení. A pokud jim Data Lake nabídne potřebné funkce, rádi přeskočí etapu přesné specifikace požadavků a čekání na jejich implementaci.
Autor: Ondřej Zýka
Information Management Principal Consultant