Know Your Data
The Ancient Greek aphorism “know thyself” is one of the Delphic maxims and was the first of three maxims inscribed in the pronaos (forecourt) of the Temple of Apollo at Delphi (source: Wikipedia).
Any knowledge comes with data. To better know yourself or better know your business, you have to perfectly understand the data about it. The more powerful our computers get, the more data we produce. Sometimes we have so much data that we cannot keep it under control. The imperative of our time should thus be “know your data”.
Use Case 1 – Data Inventory
The basic scenario is to regularly scan all your physical data stores and create a dynamic metadata repository describing what data you have and where, and how the whole data landscape evolves over time. We believe this is the basic feature all data governors dream of. The other use cases are in fact functional derivatives of this basic feature.
Use Case 2 – Semantic Data Detection
You may have ingested plenty of heterogeneous data into your data lake while having a limited chance to understand what this data is all about. You may need to assign a semantic category to each column or set of columns in each object. There are examples of semantic categories like financial amount, product code, technical identifier, customer name, date of birth, etc. You may also need to know more than just that a column contains a financial amount. For example, maybe you would like to know that the aggregated values change only slightly from day to day, and most probably such a column contains snapshots of account balances taken after each day’s system closure.
Use Case 3 – Personal Data Detection
A specific case of semantics detection is focused on personal data. In order to comply with strict rules and regulations for personal data management, you always need to know which of your data is rated as personal. Not only do you need to know that this one particular column contains the name of your customer and the other one her or his birth date. Usually, it is important to know that groups of personal data are located in the same database table or in tables directly related by a foreign key.
Use Case 4 – Change and Anomaly Detection
If you know what the classification is of each column in all your data repositories across the whole enterprise, you may need to track the dynamics—possible changes in the structure and contents of the data. One column in a table contains mostly the mobile phone numbers of your customers, but sometimes you may find their e-mail addresses there as well. Or the semantics can change immediately—what seemed to be a credit limit looks like a monthly repayment instead. Before you allow such data to be further loaded to other consuming information systems, you should check it, not only from a simple data quality perspective but also from a semantics perspective.
Use Case 5 – Do We Have Such Data?
Let’s say you want to implement a new behavioral score to better understand who is more likely to repay a consumer loan without delinquencies. In order to compute such a score, you need specific data. You know what the characteristics of such data are using a data knowledge base but need to check if the data that meets these criteria are likely to be found anywhere in your data lake.
Components
Scanner
A simple engine that scans your data. Either you can upload the data into the scanner and perform all the calculations there or you can push the algorithms down to the scanned data repository, read the data directly and use the calculation power of your existing data platform (RDBMS or big data).
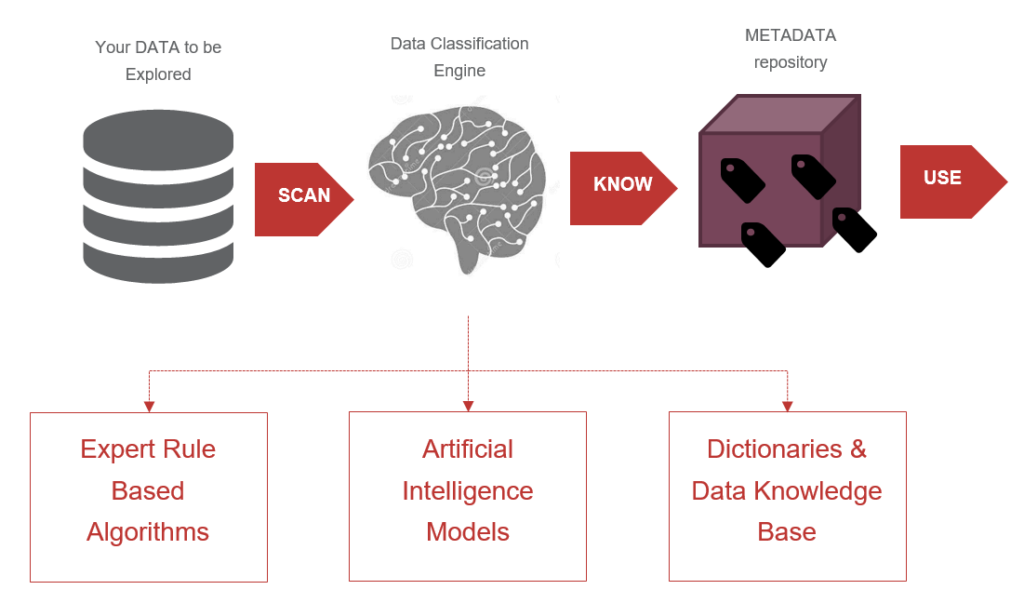
Data Classification Engine
The data classification engine consists of a set of libraries registered for the scanner. Each library performs a specific calculation (e.g., number of null values in the data set) or data detection (typically running hierarchically above the results of previous calculations and providing results of specific semantic detection).
The key feature of the engine is its modularity, which means you can design a new calculation or new detection algorithms or modify existing ones (to fine-tune them for even better results).
The algorithms are either rule based (meaning expert knowledge about banking data was used to design these algorithms) or model based (meaning statistical or data science models were used to create these algorithms).
There are also several dictionaries (like lists of street names, surnames, etc.) available. Users can also modify specific registries to customize specific rules (typically lists of various regular expressions).
Metadata Repository
All the results of the scanning, calculations and detections are stored in a simple open metadata repository with this generic metadata model:
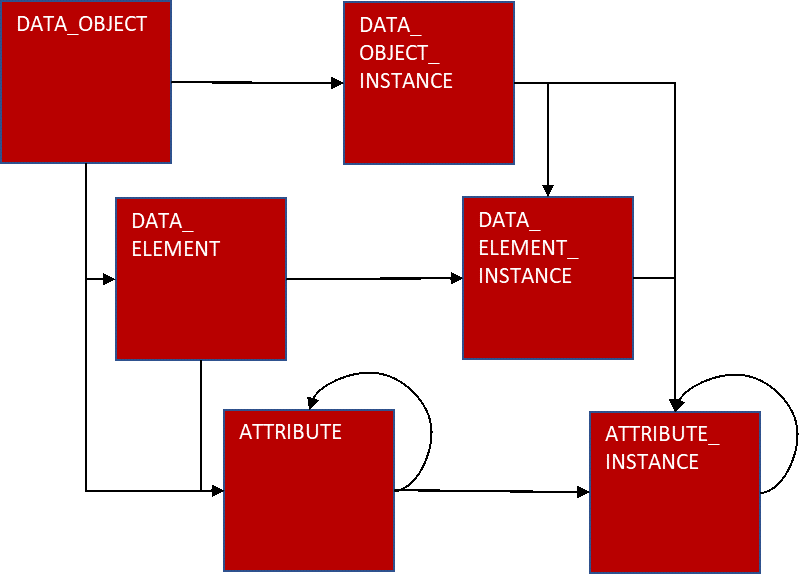
A data object (typically a database table) consists of data elements (typically database columns). After we perform all the calculations and detections, we store all the results as attributes related either to the whole data object or to a specific data element. Attributes can be organized in hierarchical structures and broken down into detailed information (e.g., the attribute histogram contains information about the distribution of numerical value ranges or the frequency of categorical data). Each scan provides data about an “instance” of data objects and elements, meaning that for a scanned object or element there may be many instances of scanned results collected over the course of time.
The metadata repository stores the same information twice: 1) in relational tables and 2) JSON structures.
Presentation Layer
Authorized users can directly access data in the metadata repository by running SQL commands or using pre-defined database views. Other users may use the graphical interface to display scanned results.
Typical BI analytical and presentation tools can also be used on the data in the metadata repository, or subsets of metadata can be exported to other consuming systems.